Sinergym with Google Cloud
In this project, we are defined some functionality based in gcloud API python in sinergym/utils/gcloud.py. Our time aim to configure a Google Cloud account and combine with Sinergym easily.
The main idea is to construct a virtual machine (VM) using Google Cloud Engine (GCE) in order to execute our Sinergym container on it. At the same time, this remote container will update a Google Cloud Bucket with experiments results and mlflow tracking server with artifacts if we configure that experiment with those options.
When an instance has finished its job, container auto-remove its host instance from Google Cloud Platform if experiments has been configured with this option.
Let’s see a detailed explanation above.
Preparing Google Cloud
1. First steps (configuration)
Firstly, it is necessary that you have a Google Cloud account set up and SDK configured (auth, invoicing, project ID, etc). If you don’t have this, it is recommended to check their documentation. Secondly, It is important to have installed Docker in order to be able to manage these containers in Google Cloud.
You can link gcloud with docker accounts using the next (see authentication methods):
$ gcloud auth configure-docker
If you don’t want to have several problems in the future with the image build and Google Cloud functionality in general, we recommend you to allow permissions for google cloud build at the beginning (see this documentation).
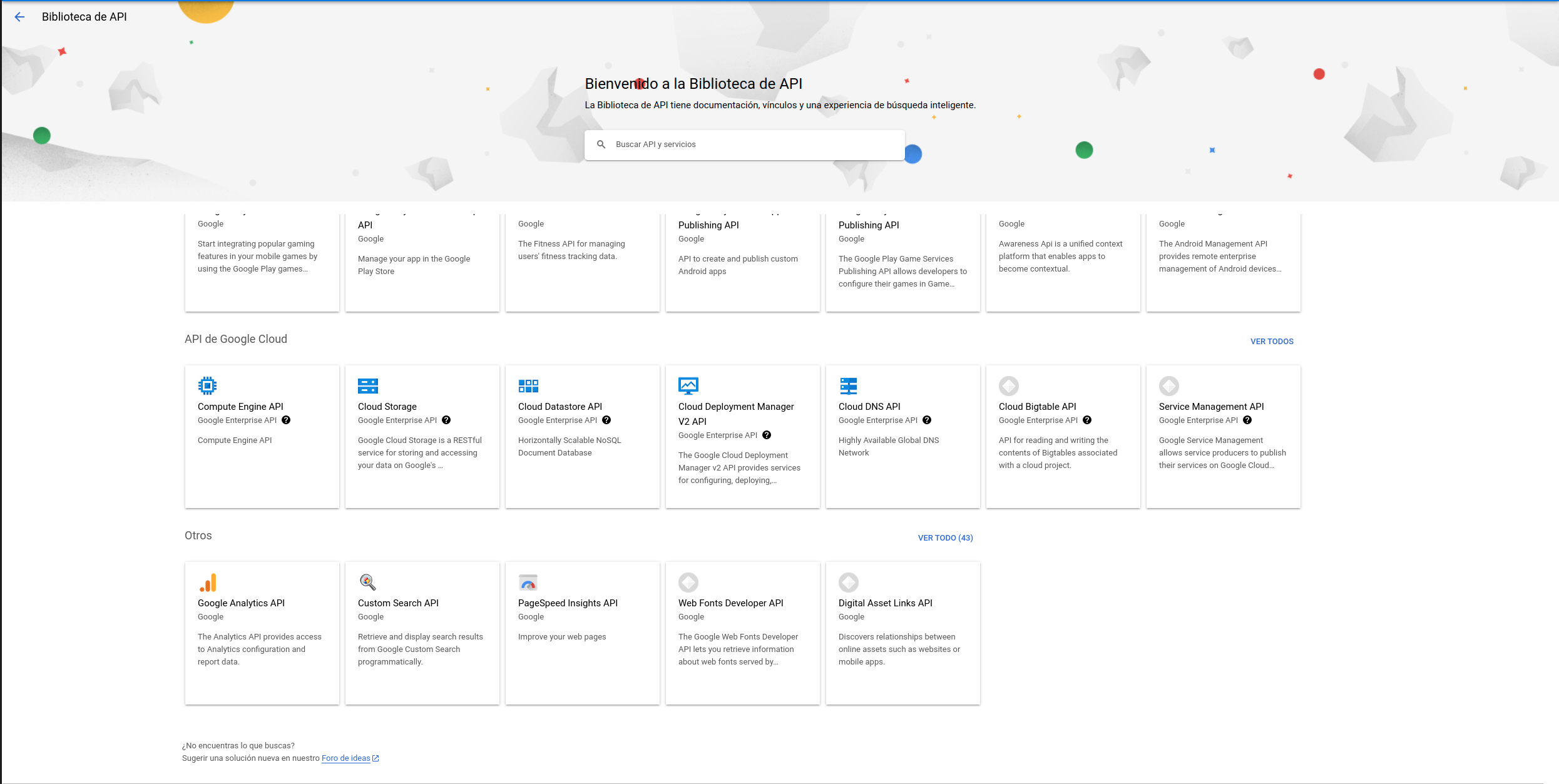
On the other hand, we are going to enable Google Cloud services in API library. These are API’s which we need currently:
Google Container Registry API.
Artifact Registry API
Cloud Run API
Compute Engine API
Cloud Logging API
Cloud Monitoring API
Cloud Functions API
Cloud Pub/Sub API
Cloud SQL Admin API
Cloud Firestore API
Cloud Datastore API
Service Usage API
Cloud storage
Gmail API
Hence, you will have to allow this services into your Google account. You can do it using gcloud client SDK:
$ gcloud services list
$ gcloud services enable artifactregistry.googleapis.com \
cloudapis.googleapis.com \
cloudbuild.googleapis.com \
containerregistry.googleapis.com \
gmail.googleapis.com \
sql-component.googleapis.com \
sqladmin.googleapis.com \
storage-component.googleapis.com \
storage.googleapis.com \
cloudfunctions.googleapis.com \
pubsub.googleapis.com \
run.googleapis.com \
serviceusage.googleapis.com \
drive.googleapis.com \
appengine.googleapis.com
Or you can use Google Cloud Platform Console:
If you have installed Sinergym and Sinergym extras. Google Cloud SDK must be linked with other python modules in order to some functionality works in the future (for example, tensorboard). Please, execute the next in your terminal:
$ gcloud auth application-default login
2. Use our container in Google Cloud Platform
Our Sinergym container is uploaded in Container Registry as a public one currently. You can use it locally:
$ docker run -it gcr.io/sinergym/sinergym:latest
If you want to use it in a GCE VM, you can execute the next:
$ gcloud compute instances create-with-container sinergym \
--container-image gcr.io/sinergym/sinergym \
--zone europe-west1-b \
--container-privileged \
--container-restart-policy never \
--container-stdin \
--container-tty \
--boot-disk-size 20GB \
--boot-disk-type pd-ssd \
--machine-type n2-highcpu-8
We have available containers in Docker Hub too. Please, visit our repository
Note
It is possible to change parameters in order to set up your own VM with your preferences (see create-with-container).
Warning
--boot-disk-size is really important, by default VM set 10GB and it isn’t enough at all for Sinergym container.
This derive in a silence error for Google Cloud Build (and you would need to check logs, which incident is not clear).
3. Use your own container
Suppose you have this repository forked and you want to upload your own container on Google Cloud and to use it. You can use cloudbuild.yaml with our Dockerfile for this purpose:
steps:
# Write in cache for quick updates
- name: "gcr.io/google.com/cloudsdktool/cloud-sdk"
entrypoint: "bash"
args: ["-c", "docker pull gcr.io/${PROJECT_ID}/sinergym:latest || exit 0"]
# Build image (using cache if it's possible)
- name: "gcr.io/google.com/cloudsdktool/cloud-sdk"
entrypoint: "docker"
args:
[
"build",
"-t",
"gcr.io/${PROJECT_ID}/sinergym:latest",
"--cache-from",
"gcr.io/${PROJECT_ID}/sinergym:latest",
"--build-arg",
"SINERGYM_EXTRAS=[DRL,gcloud]",
".",
]
# Push image built to container registry
- name: "gcr.io/google.com/cloudsdktool/cloud-sdk"
entrypoint: "docker"
args: ["push", "gcr.io/${PROJECT_ID}/sinergym:latest"]
# This container is going to be public (Change command in other case)
# - name: "gcr.io/cloud-builders/gsutil"
# args:
# [
# "iam",
# "ch",
# "AllUsers:objectViewer",
# "gs://artifacts.${PROJECT_ID}.appspot.com",
# ]
#Other options for execute build (not container)
options:
diskSizeGb: "10"
machineType: "E2_HIGHCPU_8"
timeout: 86400s
images: ["gcr.io/${PROJECT_ID}/sinergym:latest"]
This file does the next:
Write in cache for quick updates (if a older container was uploaded already).
Build image (using cache if it’s available)
Push image built to Container Registry
Make container public inner Container Registry.
There is an option section at the end of the file. Do not confuse this part with the virtual machine configuration. Google Cloud uses a helper VM to build everything mentioned above. At the same time, we are using this YAML file in order to upgrade our container because of PROJECT_ID environment variable is defined by Google Cloud SDK, so its value is your current project in Google Cloud global config.
Warning
In the same way VM needs more memory, Google Cloud Build needs at least 10GB to work correctly. In other case it may fail.
Warning
If your local computer doesn’t have enough free space it might report the same error (there isn’t difference by Google cloud error manager), so be careful.
In order to execute cloudbuild.yaml, you have to do the next:
$ gcloud builds submit \
--config ./cloudbuild.yaml .
–substitutions can be used in order to configure build parameters if they are needed.
Note
“.” in --config refers to Dockerfile, which is necessary to build container image (see build-config).
Note
In cloudbuild.yaml there is a variable named PROJECT_ID. However, it is not defined in substitutions. This is because it’s a predetermined variable by Google Cloud. When build begins “$PROJECT_ID” is set to current value in gcloud configuration (see substitutions-variables).
4. Create your VM or MIG
To create a VM that uses this container, here there is an example:
$ gcloud compute instances create-with-container sinergym \
--container-image gcr.io/sinergym/sinergym \
--zone europe-west1-b \
--container-privileged \
--container-restart-policy never \
--container-stdin \
--container-tty \
--boot-disk-size 20GB \
--boot-disk-type pd-ssd \
--machine-type n2-highcpu-8
Note
--container-restart-policy never it’s really important for a correct functionality.
Warning
If you decide enter in VM after create it immediately, it is possible container hasn’t been created yet. You can think that is an error, Google cloud should notify this. If this issue happens, you should wait for a several minutes.
To create a MIG, you need to create a machine set up template firstly, for example:
$ gcloud compute instance-templates create-with-container sinergym-template \
--container-image gcr.io/sinergym/sinergym \
--container-privileged \
--service-account storage-account@sinergym.iam.gserviceaccount.com \
--scopes https://www.googleapis.com/auth/cloud-platform,https://www.googleapis.com/auth/devstorage.full_control \
--container-env=gce_zone=europe-west1-b,gce_project_id=sinergym,MLFLOW_TRACKING_URI=http://$(gcloud compute addresses describe mlflow-ip --format='get(address)'):5000 \
--container-restart-policy never \
--container-stdin \
--container-tty \
--boot-disk-size 20GB \
--boot-disk-type pd-ssd \
--machine-type n2-highcpu-8
Note
--service-account, --scopes and --container-env parameters will be explained in Containers permission to bucket storage output. Please, read that documentation before using these parameters, since they require a previous configuration.
Then, you can create a group-instances as large as you want:
$ gcloud compute instance-groups managed create example-group \
--base-instance-name sinergym-vm \
--size 3 \
--template sinergym-template
Warning
It is possible that quote doesn’t let you have more than one VM at the same time. Hence, the rest of VM’s probably will be initializing always but never ready. If it is your case, we recommend you check your quotes here
5. Init your VM
Your virtual machine is ready! To connect you can use ssh (see gcloud-ssh):
$ gcloud compute ssh <machine-name>
Google Cloud use a Container-Optimized OS (see documentation) in VM. This SO have docker pre-installed with sinergym container.

To use this container in our machine you only have to do:
$ docker attach <container-name-or-ID>

And now you can execute your own experiments in Google Cloud! For example, you can enter in remote container with gcloud ssh and execute DRL_battery.py for the experiment you want.
Executing experiments in remote containers
This script, called DRL_battery.py, will be allocated in every remote container and it is used to execute experiments and combine it with Google Cloud Bucket, Mlflow Artifacts, auto-remove, etc:
from stable_baselines3.common.logger import configure
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.callbacks import CallbackList
from stable_baselines3 import A2C, DDPG, DQN, PPO, SAC
from stable_baselines3.common.noise import NormalActionNoise
import sinergym.utils.gcloud as gcloud
from sinergym.utils.common import RANGES_5ZONE, RANGES_IW, RANGES_DATACENTER
import gym
import sinergym
import argparse
import uuid
import mlflow
import os
from datetime import datetime
import numpy as np
from sinergym.utils.callbacks import LoggerCallback, LoggerEvalCallback
from sinergym.utils.wrappers import MultiObsWrapper, NormalizeObservation, LoggerWrapper
from sinergym.utils.rewards import *
#--------------------------------BATTERY ARGUMENTS DEFINITION---------------------------------#
parser = argparse.ArgumentParser()
# commons arguments for battery
parser.add_argument(
'--environment',
'-env',
required=True,
type=str,
dest='environment',
help='Environment name of simulation (see sinergym/__init__.py).')
parser.add_argument(
'--episodes',
'-ep',
type=int,
default=1,
dest='episodes',
help='Number of episodes for training.')
parser.add_argument(
'--algorithm',
'-alg',
type=str,
default='PPO',
dest='algorithm',
help='Algorithm used to train (possible values: PPO, A2C, DQN, DDPG, SAC).')
parser.add_argument(
'--reward',
'-rw',
type=str,
default='linear',
dest='reward',
help='Reward function used by model, by default is linear (possible values: linear, exponential).')
parser.add_argument(
'--normalization',
'-norm',
action='store_true',
dest='normalization',
help='Apply normalization to observations if this flag is specified.')
parser.add_argument(
'--multiobs',
'-mobs',
action='store_true',
dest='multiobs',
help='Apply Multi observations if this flag is specified.')
parser.add_argument(
'--logger',
'-log',
action='store_true',
dest='logger',
help='Apply Sinergym CSVLogger class if this flag is specified.')
parser.add_argument(
'--tensorboard',
'-tens',
type=str,
default=None,
dest='tensorboard',
help='Tensorboard path for logging (if not specified, tensorboard log will not be stored).')
parser.add_argument(
'--evaluation',
'-eval',
action='store_true',
dest='evaluation',
help='Evaluation is processed during training with this flag (save best model online).')
parser.add_argument(
'--eval_freq',
'-evalf',
type=int,
default=2,
dest='eval_freq',
help='Episodes executed before applying evaluation (if evaluation flag is not specified, this value is useless).')
parser.add_argument(
'--eval_length',
'-evall',
type=int,
default=2,
dest='eval_length',
help='Episodes executed during evaluation (if evaluation flag is not specified, this value is useless).')
parser.add_argument(
'--log_interval',
'-inter',
type=int,
default=1,
dest='log_interval',
help='model training log_interval parameter. See documentation since this value is different in every algorithm.')
parser.add_argument(
'--seed',
'-sd',
type=int,
default=None,
dest='seed',
help='Seed used to algorithm training.')
parser.add_argument(
'--remote_store',
'-sto',
action='store_true',
dest='remote_store',
help='Determine if sinergym output will be sent to a Google Cloud Storage Bucket.')
parser.add_argument(
'--mlflow_store',
'-mlflow',
action='store_true',
dest='mlflow_store',
help='Determine if sinergym output will be sent to a mlflow artifact storage')
parser.add_argument(
'--group_name',
'-group',
type=str,
dest='group_name',
help='This field indicate instance group name')
parser.add_argument(
'--auto_delete',
'-del',
action='store_true',
dest='auto_delete',
help='If is a GCE instance and this flag is active, that instance will be removed from GCP.')
parser.add_argument('--learning_rate', '-lr', type=float, default=.0007)
parser.add_argument('--gamma', '-g', type=float, default=.99)
parser.add_argument('--n_steps', '-n', type=int, default=5)
parser.add_argument('--gae_lambda', '-gl', type=float, default=1.0)
parser.add_argument('--ent_coef', '-ec', type=float, default=0)
parser.add_argument('--vf_coef', '-v', type=float, default=.5)
parser.add_argument('--max_grad_norm', '-m', type=float, default=.5)
parser.add_argument('--rms_prop_eps', '-rms', type=float, default=1e-05)
parser.add_argument('--buffer_size', '-bfs', type=int, default=1000000)
parser.add_argument('--learning_starts', '-ls', type=int, default=100)
parser.add_argument('--tau', '-tu', type=float, default=0.005)
# for DDPG noise only
parser.add_argument('--sigma', '-sig', type=float, default=0.1)
args = parser.parse_args()
#---------------------------------------------------------------------------------------------#
# register run name
experiment_date = datetime.today().strftime('%Y-%m-%d %H:%M')
name = args.algorithm + '-' + args.environment + \
'-episodes_' + str(args.episodes)
if args.seed:
name += '-seed_' + str(args.seed)
name += '(' + experiment_date + ')'
# Check if MLFLOW_TRACKING_URI is defined
if os.environ.get('MLFLOW_TRACKING_URI') is not None:
# Check ping to server
mlflow_ip = os.environ.get(
'MLFLOW_TRACKING_URI').split('/')[-1].split(':')[0]
# If server is not valid, setting default local path to mlflow
response = os.system("ping -c 1 " + mlflow_ip)
if response != 0:
mlflow.set_tracking_uri('file://' + os.getcwd() + '/mlruns')
# MLflow track
with mlflow.start_run(run_name=name):
# Log experiment params
mlflow.log_param('sinergym-version', sinergym.__version__)
mlflow.log_param('env', args.environment)
mlflow.log_param('episodes', args.episodes)
mlflow.log_param('algorithm', args.algorithm)
mlflow.log_param('reward', args.reward)
mlflow.log_param('normalization', bool(args.normalization))
mlflow.log_param('multi-observations', bool(args.multiobs))
mlflow.log_param('logger', bool(args.logger))
mlflow.log_param('tensorboard', args.tensorboard)
mlflow.log_param('evaluation', bool(args.evaluation))
mlflow.log_param('evaluation-frequency', args.eval_freq)
mlflow.log_param('evaluation-length', args.eval_length)
mlflow.log_param('log-interval', args.log_interval)
mlflow.log_param('seed', args.seed)
mlflow.log_param('remote-store', bool(args.remote_store))
mlflow.log_param('learning_rate', args.learning_rate)
mlflow.log_param('n_steps', args.n_steps)
mlflow.log_param('gamma', args.gamma)
mlflow.log_param('gae_lambda', args.gae_lambda)
mlflow.log_param('ent_coef', args.ent_coef)
mlflow.log_param('buffer_size', args.buffer_size)
mlflow.log_param('vf_coef', args.vf_coef)
mlflow.log_param('max_grad_norm', args.max_grad_norm)
mlflow.log_param('rms_prop_eps', args.rms_prop_eps)
mlflow.log_param('learning_starts', args.learning_starts)
mlflow.log_param('tau', args.tau)
mlflow.log_param('sigma', args.sigma)
# Environment construction (with reward specified)
if args.reward == 'linear':
env = gym.make(args.environment, reward=LinearReward())
elif args.reward == 'exponential':
env = gym.make(args.environment, reward=ExpReward())
else:
raise RuntimeError('Reward function specified is not registered.')
# env wrappers (optionals)
if args.normalization:
env = NormalizeObservation(env)
if args.logger:
env = LoggerWrapper(env)
if args.multiobs:
env = MultiObsWrapper(env)
######################## TRAINING ########################
# env wrappers (optionals)
if args.normalization:
# We have to know what dictionary ranges to use
norm_range = None
env_type = args.environment.split('-')[2]
if env_type == 'datacenter':
range = RANGES_5ZONE
elif env_type == '5Zone':
range = RANGES_IW
elif env_type == 'IWMullion':
range = RANGES_DATACENTER
else:
raise NameError('env_type is not valid, check environment name')
env = NormalizeObservation(env, ranges=range)
if args.logger:
env = LoggerWrapper(env)
if args.multiobs:
env = MultiObsWrapper(env)
# Defining model(algorithm)
model = None
#--------------------------DQN---------------------------#
if args.algorithm == 'DQN':
model = DQN('MlpPolicy', env, verbose=1,
learning_rate=args.learning_rate,
buffer_size=args.buffer_size,
learning_starts=50000,
batch_size=32,
tau=args.tau,
gamma=args.gamma,
train_freq=4,
gradient_steps=1,
target_update_interval=10000,
exploration_fraction=.1,
exploration_initial_eps=1.0,
exploration_final_eps=.05,
max_grad_norm=args.max_grad_norm,
seed=args.seed,
tensorboard_log=args.tensorboard)
#--------------------------------------------------------#
#--------------------------DDPG--------------------------#
# The noise objects for DDPG
elif args.algorithm == 'DDPG':
if args.sigma:
n_actions = env.action_space.shape[-1]
action_noise = NormalActionNoise(mean=np.zeros(
n_actions), sigma=0.1 * np.ones(n_actions))
model = DDPG("MlpPolicy",
env,
action_noise=action_noise,
verbose=1,
seed=args.seed,
tensorboard_log=args.tensorboard)
#--------------------------------------------------------#
#--------------------------A2C---------------------------#
elif args.algorithm == 'A2C':
model = A2C('MlpPolicy', env, verbose=1,
learning_rate=args.learning_rate,
n_steps=args.n_steps,
gamma=args.gamma,
gae_lambda=args.gae_lambda,
ent_coef=args.ent_coef,
vf_coef=args.vf_coef,
max_grad_norm=args.max_grad_norm,
rms_prop_eps=args.rms_prop_eps,
seed=args.seed,
tensorboard_log=args.tensorboard)
#--------------------------------------------------------#
#--------------------------PPO---------------------------#
elif args.algorithm == 'PPO':
model = PPO('MlpPolicy', env, verbose=1,
learning_rate=args.learning_rate,
n_steps=args.n_steps,
batch_size=64,
n_epochs=10,
gamma=args.gamma,
gae_lambda=args.gae_lambda,
clip_range=.2,
ent_coef=0,
vf_coef=.5,
max_grad_norm=args.max_grad_norm,
seed=args.seed,
tensorboard_log=args.tensorboard)
#--------------------------------------------------------#
#--------------------------SAC---------------------------#
elif args.algorithm == 'SAC':
model = SAC(policy='MlpPolicy',
env=env,
seed=args.seed,
tensorboard_log=args.tensorboard)
#--------------------------------------------------------#
#-------------------------ERROR?-------------------------#
else:
raise RuntimeError('Algorithm specified is not registered.')
#--------------------------------------------------------#
# Calculating n_timesteps_episode for training
n_timesteps_episode = env.simulator._eplus_one_epi_len / \
env.simulator._eplus_run_stepsize
timesteps = args.episodes * n_timesteps_episode
# For callbacks processing
env_vec = DummyVecEnv([lambda: env])
# Using Callbacks for training
callbacks = []
# Set up Evaluation and saving best model
if args.evaluation:
eval_callback = LoggerEvalCallback(
env_vec,
best_model_save_path='best_model/' + name + '/',
log_path='best_model/' + name + '/',
eval_freq=n_timesteps_episode *
args.eval_freq,
deterministic=True,
render=False,
n_eval_episodes=args.eval_length)
callbacks.append(eval_callback)
# Set up tensorboard logger
if args.tensorboard:
log_callback = LoggerCallback(sinergym_logger=bool(args.logger))
callbacks.append(log_callback)
# lets change default dir for TensorboardFormatLogger only
tb_path = args.tensorboard + '/' + name
new_logger = configure(tb_path, ["tensorboard"])
model.set_logger(new_logger)
callback = CallbackList(callbacks)
# Training
model.learn(
total_timesteps=timesteps,
callback=callback,
log_interval=args.log_interval)
model.save(env.simulator._env_working_dir_parent + '/' + name)
# If mlflow artifacts store is active
if args.mlflow_store:
# Code for send output and tensorboard to mlflow artifacts.
mlflow.log_artifacts(
local_dir=env.simulator._env_working_dir_parent,
artifact_path=name + '/')
if args.evaluation:
mlflow.log_artifacts(
local_dir='best_model/' + name + '/',
artifact_path='best_model/' + name + '/')
# If tensorboard is active (in local) we should send to mlflow
if args.tensorboard and 'gs://experiments-storage' not in args.tensorboard:
mlflow.log_artifacts(
local_dir=args.tensorboard + '/' + name + '/',
artifact_path=os.path.abspath(args.tensorboard).split('/')[-1] + '/' + name + '/')
# Store all results if remote_store flag is True (Google Cloud Bucket for
# experiments)
if args.remote_store:
# Initiate Google Cloud client
client = gcloud.init_storage_client()
# Code for send output and tensorboard to common resource here.
gcloud.upload_to_bucket(
client,
src_path=env.simulator._env_working_dir_parent,
dest_bucket_name='experiments-storage',
dest_path=name)
if args.evaluation:
gcloud.upload_to_bucket(
client,
src_path='best_model/' + name + '/',
dest_bucket_name='experiments-storage',
dest_path='best_model/' + name + '/')
# If tensorboard is active (in local) we should send to bucket
if args.tensorboard and 'gs://experiments-storage' not in args.tensorboard:
gcloud.upload_to_bucket(
client,
src_path=args.tensorboard + '/' + name + '/',
dest_bucket_name='experiments-storage',
dest_path=os.path.abspath(args.tensorboard).split('/')[-1] + '/' + name + '/')
# gcloud.upload_to_bucket(
# client,
# src_path='mlruns/',
# dest_bucket_name='experiments-storage',
# dest_path='mlruns/')
# End mlflow run
mlflow.end_run()
# If it is a Google Cloud VM and experiment flag auto_delete has been
# activated, shutdown remote machine when ends
if args.group_name and args.auto_delete:
token = gcloud.get_service_account_token()
gcloud.delete_instance_MIG_from_container(args.group_name, token)
Note
DRL_battery.py is able to be used to local experiments into client computer. For example, --auto_delete parameter will have no effect in experiment. This experiments results could be sent to bucket and mlflow artifacts if it is specified. We will see it.
The list of parameter is pretty large. Let’s see it:
--environmentor-env: Environment name you want to use (see Environments)--episodesor-ep: Number of episodes you want to train agent in simulation (Depending on environment episode length can be different)--algorithmor-alg: Algorithm you want to use to train (Currently, it is available PPO, A2C, DQN, DDPG and SAC)--rewardor-rw: Reward class you want to use for reward function. Currently, possible values are “linear” and “exponential”(see Rewards).--normalizationor-norm: Apply normalization wrapper to observations during training. If it isn’t specified wrapper will not be applied (see Wrappers).--multiobsor-mobs: Apply Multi-Observation wrapper to observations during training. If it isn’t specified wrapper will not be applied (see Wrappers).--loggeror-log: Apply Sinergym logger wrapper during training. If it isn’t specified wrapper will not be applied (see Wrappers and Logger).--tensorboardor-tens: This parameter will contain a path-file or path-remote-bucket to allocate tensorboard training logs. If it isn’t specified this log will be deactivate (see DRL Logger).--evaluationor-eval: If it is specified, evaluation callback will be activate, else model evaluation will be deactivate during training (see Deep Reinforcement Learning Integration).--eval_freqor-evalf: Only if--evaluationflag has been written. Episode frequency for evaluation.--eval_lengthor-evall: Only if--evaluationflag has been written. Number of episodes for each evaluation.--log_intervalor-inter: This parameter is used forlearn()method in each algorithm. It is important specify a correct value.--seedor-sd: Seed for training, random components in process will be able to be recreated.--remote_storeor-sto: Determine if sinergym output and tensorboard log (when a local path is specified and not a remote bucket path) will be sent to a common resource (Bucket), else will be allocate in remote container memory only.--mlflow_storeor-mlflow: Determine if sinergym output and tensorboard log (when a local path is specified and not a remote bucket path) will be sent to a Mlflow Artifact, else will be allocate in remote container memory only.--group_nameor-group: It specify to which MIG the host instance belongs, it is important if –auto-delete is activated.--auto_deleteor-del: Whether this parameter is specified, remote instance will be auto removed when its job has finished.algorithm hyperparameters: Execute
python DRL_battery --helpfor more information.
Warning
For a correct auto_delete functionality, please, use MIG’s instead of individual instances.
This script do the next:
Setting an appropriate name for the experiment. Following the next format:
<algorithm>-<environment_name>-episodes<episodes_int>-seed<seed_value>(<experiment_date>)Starting Mlflow track experiment with that name, if mlflow server is not available, it will be used an local path (./mlruns) in remote container.
Log all MlFlow parameters (including sinergym.__version__).
Setting reward function specified in
--rewardparameter.Setting wrappers specified in environment.
Defining model algorithm using hyperparameters.
Calculate training timesteps using number of episodes.
Setting up evaluation callback if it has been specified.
Setting up Tensorboard logger callback if it has been specified.
Training with environment.
If
--remote_storehas been specified, saving all outputs in Google Cloud Bucket. If--mlflow_storehas been specified, saving all outputs in Mlflow run artifact.Auto-delete remote container in Google Cloud Platform when parameter
--auto_deletehas been specified.
Containers permission to bucket storage output
As you see in sinergym template explained in 4. Create your VM or MIG, it is specified --scope, --service-account and --container-env. This aim to remote_store option in DRL_battery.py works correctly.
Those parameters provide each container with permissions to write in the bucket and manage Google Cloud Platform (auto instance remove function).
Container environment variables indicate zone, project_id and mlflow tracking server uri need it in Mlflow tracking server set up.
Hence, it is necessary to set up this service account and give privileges in order to that objective. Then, following Google authentication documentation we will do the next:
$ gcloud iam service-accounts create storage-account
$ gcloud projects add-iam-policy-binding PROJECT_ID --member="serviceAccount:storage-account@PROJECT_ID.iam.gserviceaccount.com" --role="roles/owner"
$ gcloud iam service-accounts keys create PROJECT_PATH/google-storage.json --iam-account=storage-account@PROJECT_ID.iam.gserviceaccount.com
$ export GOOGLE_CLOUD_CREDENTIALS= PROJECT_PATH/google-storage.json
In short, we create a new service account called storage-account. Then, we dote this account with roles/owner permission. The next step is create a file key (json) called google-storage.json in our project root (gitignore will ignore this file in remote). Finally, we export this file in GOOGLE_CLOUD_CREDENTIALS in our local computer in order to gcloud SDK knows that it has to use that token to authenticate.
Remote Tensorboard log
In --tensorboard parameter we have to specify a local path or a Bucket path.
If we specify a local path, tensorboard logs will be stored in remote containers memory. If you have specified --remote_store or --mlflow_store, this logs will be sent to those remote storages when experiment finishes.
One of the strengths of Tensorboard is the ability to see the data in real time as the training is running. Thus, it is recommended to define in --tensorboard the bucket path directly in order to send that information
as the training is generating it (see this issue for more information). In our project we have gs://experiments-storage/tensorboard_log but you can have whatever you want.
Note
If in --tensorboard you have specified a gs path, --remote_store or --mlflow_store parameters don’t store tensorboard logs.
Warning
Whether you have written a bucket path, don’t write / at the end (gs://experiments-storage/tensorboard_log/), this causes that real-time remote storage doesn’t work correctly.
Warning
In the case that gs URI isn’t recognized. Maybe is due to your tensorboard installation hasn’t got access your google account. Try gcloud auth application-default login command.
Visualize remote Tensorboard log in real-time
- You have two options:
Create a remote server with tensorboard service deployed.
Init that service in your local computer, reading from the bucket log, and access to the visualization in http://localhost:6006
The second options is enough since we can read from bucket when we need directly and shut down local service when we finish.
$ tensorboard --logdir gs://experiments-storage/tensorboard_log/
Mlflow tracking server set up
Mlflow tracking server can be set up into your google account in order to organize your own experiments (Mlflow). You can separate back-end (SQL database) from tracking server. In this way, you can shut down or delete server instance without loose your experiments run data, since SQL is always up. Let’s see how:
#!/bin/bash
# This scrip is used to build a mlflow server in Google Cloud, it is important
# to set up account previously.
# Please, visit our documentation here --> https://jajimer.github.io/sinergym/build/html/index.html
# Step 0 - Store all parameters
PROJECT_ID=$1
BUCKET_NAME=$2
ZONE=$3
REGION=${ZONE::-2}
DB_ROOT_PASSWORD=$4
MACHINE_TYPE=e2-medium
MLFLOW_IMAGE=kaysush/mlflow:1.14.1
CLOUD_SQL_PROXY_IMAGE=gcr.io/cloudsql-docker/gce-proxy:1.19.1
MYSQL_INSTANCE=${PROJECT_ID}:${REGION}:mlflow-backend
# Step 1 - Service account for mlflow service
echo "Creating Service account for mlflow service [mlflow-tracking-sa]..."
gcloud iam service-accounts create mlflow-tracking-sa --description="Service Account to run the MLFLow tracking server" --display-name="MLFlow tracking SA"
# Step 2 - Artifact used by mlflow to store all runs information
echo "Creating Back-end artifact bucket [$BUCKET_NAME]..."
gsutil mb gs://$BUCKET_NAME
# Step 3 - CLoud SQL, instance with SQL and "mlflow" database inner
echo "Creating sql instance with mlflow database [mlflow-backend]..."
gcloud sql instances create mlflow-backend --tier=db-f1-micro --region=${REGION} --root-password=${DB_ROOT_PASSWORD} --storage-type=SSD
gcloud sql databases create mlflow --instance=mlflow-backend
# Step 4 - IAM: Provisioning service account privileges in order to manipulate bucket and back-end
echo "Creating service account privileges to use Back-end [roles/cloudsql.editor]..."
gsutil iam ch "serviceAccount:mlflow-tracking-sa@${PROJECT_ID}.iam.gserviceaccount.com:roles/storage.admin" gs://${BUCKET_NAME}
gcloud projects add-iam-policy-binding ${PROJECT_ID} --member="serviceAccount:mlflow-tracking-sa@${PROJECT_ID}.iam.gserviceaccount.com" --role=roles/cloudsql.editor
# Step 5 - Creating start_mlflow_tracking.sh to initialize instance
echo "Creating start_mlflow_tracking.sh to initialize instance..."
cat <<EOF >./start_mlflow_tracking.sh
echo "Starting Cloud SQL Proxy'"
docker run -d --name mysql --net host -p 3306:3306 $CLOUD_SQL_PROXY_IMAGE /cloud_sql_proxy -instances $MYSQL_INSTANCE=tcp:0.0.0.0:3306
echo "Starting mlflow-tracking server"
docker run -d --name mlflow-tracking --net host -p 5000:5000 $MLFLOW_IMAGE mlflow server --backend-store-uri mysql+pymysql://root:${DB_ROOT_PASSWORD}@localhost/mlflow --default-artifact-root gs://${BUCKET_NAME}/mlflow_artifacts/ --host 0.0.0.0
echo "Altering IPTables"
iptables -A INPUT -p tcp --dport 5000 -j ACCEPT
EOF
# Step 6 - Uploading start script and deleting from local
echo "Uploading start_mlflow_tracking.sh at gs://${BUCKET_NAME}/scripts/start_mlflow_tracking.sh..."
gsutil cp ./start_mlflow_tracking.sh gs://${BUCKET_NAME}/scripts/start_mlflow_tracking.sh
echo "Deleting temporal local script [start_mlflow_tracking.sh]"
rm ./start_mlflow_tracking.sh
#Step 7 - creating static external ip for mlflow server
echo "Creating static external ip for mlflow-tracking-server [mlflow-ip]"
gcloud compute addresses create mlflow-ip \
--region europe-west1
# Step 8 - Compute Instance
echo "Deploying remote server [mlflow-tracking-server]..."
gcloud compute --project=$PROJECT_ID instances create mlflow-tracking-server \
--zone=$ZONE \
--machine-type=$MACHINE_TYPE \
--subnet=default \
--network-tier=PREMIUM \
--metadata=startup-script-url=gs://${BUCKET_NAME}/scripts/start_mlflow_tracking.sh \
--maintenance-policy=MIGRATE \
--service-account=mlflow-tracking-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--scopes=https://www.googleapis.com/auth/cloud-platform \
--tags=mlflow-tracking-server \
--image=cos-77-12371-1109-0 \
--image-project=cos-cloud \
--boot-disk-size=10GB \
--boot-disk-type=pd-balanced \
--boot-disk-device-name=mlflow-tracking-server \
--no-shielded-secure-boot \
--shielded-vtpm \
--shielded-integrity-monitoring \
--reservation-affinity=any \
--address $(gcloud compute addresses describe mlflow-ip --format='get(address)')
# Step 8 - Firewall
echo "Creating firewall rules [allow-mlflow-tracking]..."
gcloud compute firewall-rules create allow-mlflow-tracking --network default --priority 1000 --direction ingress --action allow --target-tags mlflow-tracking-server --source-ranges 0.0.0.0/0 --rules tcp:5000 --enable-logging
This bash script defines all the process to configure this functionality automatically. (Once you execute it you don’t have to use this script anymore). The arguments it needs are: PROJECT_ID, BUCKET_NAME, ZONE and DB_ROOT_PASSWORD.
This script do the next for you:
Creating Service account for mlflow service [mlflow-tracking-sa].
Creating Back-end artifact bucket.
Creating sql instance with root password specified in argument 4.
Creating mlflow database inner SQL instance.
Creating service account privileges to use Back-end [roles/cloudsql.editor]
Generating an automatic script called start_mlflow_tracking.sh and sending to
gs://<BUCKET_NAME>/scripts/Deleting local start_mlflow_tracking.sh file.
Creating static external ip for mlflow-tracking-server
Deploying remote server [mlflow-tracking-server]
Step 8 is very important, this allows you to delete server instance and create again when you need it without redefining server ip in sinergym-template for remote container experiments. Notice that server instance creation use service account for mlflow, with this configuration mlflow can read from SQL server. In 4. Create your VM or MIG it is specified MLFLOW_TRACKING_URI container environment variable using that external static ip.
Warning
It is important execute this script before create sinergym-template instances in order to anotate mlflow-server-ip.
Note
If you want to change any backend configuration, you can change any parameter of the script bellow.
Note
Whether you have written --mlflow_store, Sinergym outputs will be sent to mlflow server as artifacts. These artifacts will be stored in the same bucket where is allocated gs://<BUCKET_NAME>
Google Cloud Alerts
Google Cloud Platform include functionality in order to trigger some events and generate alerts in consequence. Then, a trigger has been created in our gcloud project which aim to advertise when an experiment has finished. This alert can be captured in several ways (slack, sms, email, etc). If you want to do the same, please, check Google Cloud Alerts documentation here.