Sinergym Google Cloud API
In this project, an API based on RESTfull API for gcloud has been designed and developed in order to use Google Cloud infrastructure directly writing experiments definition ir our personal computer.
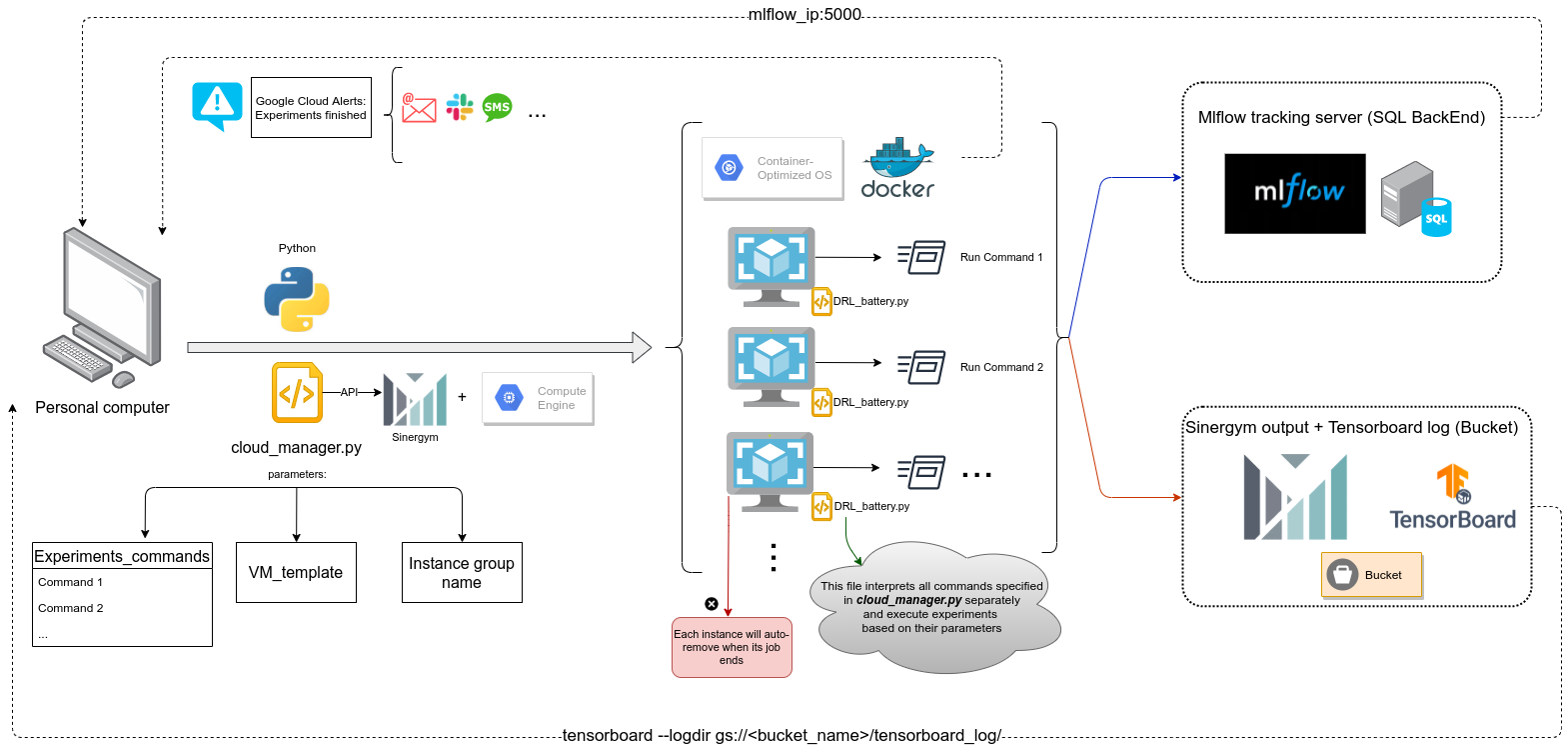
From our personal computer, we send a list of experiments we want to be executed in Google Cloud, using cloud_manager.py script for that purpose. An instance will be created for every experiment defined. Each VM send MLFlow logs to MLFlow tracking server (see Mlflow tracking server set up for details). On the other hand, Sinergym output and Tensorboard output are sent to a Google Cloud Bucket (see Remote Tensorboard log for details)
When an instance has finished its job, container auto-remove its host instance from Google Cloud Platform. Whether an instance is the last in the MIG, that container auto-remove the empty MIG too.
Warning
Don’t try to remove an instance inner MIG directly using Google Cloud API REST, it needs to be executed from MIG to work. Some other problems (like wrong API REST documentation) have been solved in our API. We recommend you use this API directly.
Let’s see a detailed explanation above.
Executing API
Our objective is defining a set of experiments in order to execute them in a Google Cloud remote container each one. For this, cloud_manager.py has been created in repository root. This file must be used in our local computer:
import argparse
from time import sleep
from pprint import pprint
import sinergym.utils.gcloud as gcloud
from google.cloud import storage
import google.api_core.exceptions
parser = argparse.ArgumentParser(
description='Process for run experiments in Google Cloud')
parser.add_argument(
'--project_id',
'-id',
type=str,
dest='project',
help='Your Google Cloud project ID.')
parser.add_argument(
'--zone',
'-zo',
type=str,
default='europe-west1-b',
dest='zone',
help='service Engine zone to deploy to.')
parser.add_argument(
'--template_name',
'-tem',
type=str,
default='sinergym-template',
dest='template_name',
help='Name of template previously created in gcloud account to generate VM copies.')
parser.add_argument(
'--group_name',
'-group',
type=str,
default='sinergym-group',
dest='group_name',
help='Name of instance group(MIG) will be created during experimentation.')
parser.add_argument(
'--experiment_commands',
'-cmds',
default=['python3 ./algorithm/DQN.py -env Eplus-demo-v1 -ep 1 -'],
nargs='+',
dest='commands',
help='list of commands for DRL_battery.py you want to execute remotely.')
args = parser.parse_args()
print('Init Google cloud service API...')
service = gcloud.init_gcloud_service()
print('Init Google Cloud Storage Client...')
client = gcloud.init_storage_client()
# Create instance group
n_experiments = len(args.commands)
print('Creating instance group(MIG) for experiments ({} instances)...'.format(
n_experiments))
response = gcloud.create_instance_group(
service=service,
project=args.project,
zone=args.zone,
size=n_experiments,
template_name=args.template_name,
group_name=args.group_name)
pprint(response)
# Wait for the machines to be fully created.
print(
'{0} status is {1}.'.format(
response['operationType'],
response['status']))
if response['status'] != 'DONE':
response = gcloud.wait_for_operation(
service,
args.project,
args.zone,
operation=response['id'],
operation_type=response['operationType'])
pprint(response)
print('MIG created.')
# If storage exists it will be used, else it will be created previously by API
print('Looking for experiments storage')
try:
bucket = gcloud.get_bucket(client, bucket_name='experiments-storage')
print(
'Bucket {} found, this storage will be used when experiments finish.'.format(
bucket.name))
except(google.api_core.exceptions.NotFound):
print('Any bucket found into your Google account, generating new one...')
bucket = gcloud.create_bucket(
client,
bucket_name='experiments-storage',
location='EU')
# List VM names
print('Looking for instance names... (waiting for they are visible too)')
# Sometimes, although instance group insert status is DONE, isn't visible
# for API yet. Hence, we have to wait for with a loop...
instances = []
while len(instances) < n_experiments:
instances = gcloud.list_instances(
service=service,
project=args.project,
zone=args.zone,
base_instances_names=args.group_name)
sleep(3)
print(instances)
# Number of machines should be the same than commands
# Processing commands and adding group id to the petition
for i in range(len(args.commands)):
args.commands[i] += ' --group_name ' + args.group_name
# Execute a comand in every container inner VM
print('Sending commands to every container VM... (waiting for container inner VM is ready too)')
for i, instance in enumerate(instances):
container_id = None
# Obtain container id inner VM
while not container_id:
container_id = gcloud.get_container_id(instance_name=instance)
sleep(5)
# Execute command in container
gcloud.execute_remote_command_instance(
container_id=container_id,
instance_name=instance,
experiment_command=args.commands[i])
print(
'command {} has been sent to instance {}(container: {}).'.format(
args.commands[i],
instance,
container_id))
print('All VM\'s are working correctly, see Google Cloud Platform Console.')
This script uses the following parameters:
--project_idor-id: Your Google Cloud project id must be specified.--zoneor-zo: Zone for your project (default is europe-west1-b).--template_nameor-tem: Template used to generate VM’s clones, defined in your project previously (see 4. Create your VM or MIG).--group_nameor-group: Instance group name you want. All instances inner MIG will have this name concatenated with a random str.--experiment_commandsor-cmds: Experiment definitions list using python command format (for information about its format, see Receiving experiments in remote containers).
Here is an example bash code to execute the script:
$ python cloud_manager.py \
--project_id sinergym \
--zone europe-west1-b \
--template_name sinergym-template \
--group_name sinergym-group \
--experiment_commands
'python3 DRL_battery.py --environment Eplus-5Zone-hot-discrete-v1 --episodes 2 --algorithm DQN --logger --log_interval 1 --seed 58 --evaluation --eval_freq 1 --eval_length 1 --tensorboard ./tensorboard_log --remote_store' \
'python3 DRL_battery.py --environment Eplus-5Zone-hot-continuous-v1 --episodes 3 --algorithm PPO --logger --log_interval 300 --seed 52 --evaluation --eval_freq 1 --eval_length 1 --tensorboard ./tensorboard_log --remote_store'
This example generates only 2 machines inner an instance group in your Google Cloud Platform because of you have defined two experiments. If you defined more experiments, more machines will be created by API.
This script do the next:
Counting commands list in
--experiment_commandsparameter and generate an Managed Instance Group (MIG) with the same size.Waiting for process 1 finishes.
If experiments-storage Bucket doesn’t exist, this script create one to store experiment result, else use the current one.
Looking for instance names generated randomly by Google cloud once MIG is created (waiting for instances generation if they haven’t been created yet).
To each commands experiment, it is added
--group_nameoption in order to each container see what is its own MIG (useful to auto-remove them).Looking for id container about each instance. This process waits for containers are initialize, since instance is initialize earlier than inner container.
Sending each experiment command in containers from each instance using an SSH connection.
Note
Because of its real-time process. Some containers, instance list action and others could take time. In that case, the API wait a process finish to execute the next (when it is necessary).
Note
This script uses gcloud API in background. Methods developed and used to this issues can be seen in sinergym/sinergym/utils/gcloud.py or in API reference. Remember to configure Google Cloud account correctly before use this functionality.
Receiving experiments in remote containers
This script, called DRL_battery.py, will be allocated in every remote container and it is used to understand experiments command exposed above by cloud_manager.py (--experiment_commands):
from stable_baselines3.common.logger import configure
from stable_baselines3.common.vec_env import DummyVecEnv
from stable_baselines3.common.callbacks import CallbackList
from stable_baselines3 import A2C, DDPG, DQN, PPO, SAC
from stable_baselines3.common.noise import NormalActionNoise
import sinergym.utils.gcloud as gcloud
from sinergym.utils.common import RANGES_5ZONE, RANGES_IW, RANGES_DATACENTER
import gym
import sinergym
import argparse
import uuid
import mlflow
import os
from datetime import datetime
import numpy as np
from sinergym.utils.callbacks import LoggerCallback, LoggerEvalCallback
from sinergym.utils.wrappers import MultiObsWrapper, NormalizeObservation, LoggerWrapper
from sinergym.utils.rewards import *
#--------------------------------BATTERY ARGUMENTS DEFINITION---------------------------------#
parser = argparse.ArgumentParser()
# commons arguments for battery
parser.add_argument(
'--environment',
'-env',
required=True,
type=str,
dest='environment',
help='Environment name of simulation (see sinergym/__init__.py).')
parser.add_argument(
'--episodes',
'-ep',
type=int,
default=1,
dest='episodes',
help='Number of episodes for training.')
parser.add_argument(
'--algorithm',
'-alg',
type=str,
default='PPO',
dest='algorithm',
help='Algorithm used to train (possible values: PPO, A2C, DQN, DDPG, SAC).')
parser.add_argument(
'--reward',
'-rw',
type=str,
default='linear',
dest='reward',
help='Reward function used by model, by default is linear (possible values: linear, exponential).')
parser.add_argument(
'--normalization',
'-norm',
action='store_true',
dest='normalization',
help='Apply normalization to observations if this flag is specified.')
parser.add_argument(
'--multiobs',
'-mobs',
action='store_true',
dest='multiobs',
help='Apply Multi observations if this flag is specified.')
parser.add_argument(
'--logger',
'-log',
action='store_true',
dest='logger',
help='Apply Sinergym CSVLogger class if this flag is specified.')
parser.add_argument(
'--tensorboard',
'-tens',
type=str,
default=None,
dest='tensorboard',
help='Tensorboard path for logging (if not specified, tensorboard log will not be stored).')
parser.add_argument(
'--evaluation',
'-eval',
action='store_true',
dest='evaluation',
help='Evaluation is processed during training with this flag (save best model online).')
parser.add_argument(
'--eval_freq',
'-evalf',
type=int,
default=2,
dest='eval_freq',
help='Episodes executed before applying evaluation (if evaluation flag is not specified, this value is useless).')
parser.add_argument(
'--eval_length',
'-evall',
type=int,
default=2,
dest='eval_length',
help='Episodes executed during evaluation (if evaluation flag is not specified, this value is useless).')
parser.add_argument(
'--log_interval',
'-inter',
type=int,
default=1,
dest='log_interval',
help='model training log_interval parameter. See documentation since this value is different in every algorithm.')
parser.add_argument(
'--seed',
'-sd',
type=int,
default=None,
dest='seed',
help='Seed used to algorithm training.')
parser.add_argument(
'--remote_store',
'-sto',
action='store_true',
dest='remote_store',
help='Determine if sinergym output will be sent to a common resource')
parser.add_argument(
'--group_name',
'-group',
type=str,
dest='group_name',
help='This field indicate instance group name')
parser.add_argument('--learning_rate', '-lr', type=float, default=.0007)
parser.add_argument('--gamma', '-g', type=float, default=.99)
parser.add_argument('--n_steps', '-n', type=int, default=5)
parser.add_argument('--gae_lambda', '-gl', type=float, default=1.0)
parser.add_argument('--ent_coef', '-ec', type=float, default=0)
parser.add_argument('--vf_coef', '-v', type=float, default=.5)
parser.add_argument('--max_grad_norm', '-m', type=float, default=.5)
parser.add_argument('--rms_prop_eps', '-rms', type=float, default=1e-05)
parser.add_argument('--buffer_size', '-bfs', type=int, default=1000000)
parser.add_argument('--learning_starts', '-ls', type=int, default=100)
parser.add_argument('--tau', '-tu', type=float, default=0.005)
# for DDPG noise only
parser.add_argument('--sigma', '-sig', type=float, default=0.1)
args = parser.parse_args()
#---------------------------------------------------------------------------------------------#
# register run name
experiment_date = datetime.today().strftime('%Y-%m-%d %H:%M')
name = args.algorithm + '-' + args.environment + \
'-episodes_' + str(args.episodes)
if args.seed:
name += '-seed_' + str(args.seed)
name += '(' + experiment_date + ')'
# MLflow track
with mlflow.start_run(run_name=name):
# Log experiment params
mlflow.log_param('sinergym-version', sinergym.__version__)
mlflow.log_param('env', args.environment)
mlflow.log_param('episodes', args.episodes)
mlflow.log_param('algorithm', args.algorithm)
mlflow.log_param('reward', args.reward)
mlflow.log_param('normalization', bool(args.normalization))
mlflow.log_param('multi-observations', bool(args.multiobs))
mlflow.log_param('logger', bool(args.logger))
mlflow.log_param('tensorboard', args.tensorboard)
mlflow.log_param('evaluation', bool(args.evaluation))
mlflow.log_param('evaluation-frequency', args.eval_freq)
mlflow.log_param('evaluation-length', args.eval_length)
mlflow.log_param('log-interval', args.log_interval)
mlflow.log_param('seed', args.seed)
mlflow.log_param('remote-store', bool(args.seed))
mlflow.log_param('learning_rate', args.learning_rate)
mlflow.log_param('n_steps', args.n_steps)
mlflow.log_param('gamma', args.gamma)
mlflow.log_param('gae_lambda', args.gae_lambda)
mlflow.log_param('ent_coef', args.ent_coef)
mlflow.log_param('buffer_size', args.buffer_size)
mlflow.log_param('vf_coef', args.vf_coef)
mlflow.log_param('max_grad_norm', args.max_grad_norm)
mlflow.log_param('rms_prop_eps', args.rms_prop_eps)
mlflow.log_param('learning_starts', args.learning_starts)
mlflow.log_param('tau', args.tau)
mlflow.log_param('sigma', args.sigma)
# Environment construction (with reward specified)
if args.reward == 'linear':
env = gym.make(args.environment, reward=LinearReward())
elif args.reward == 'exponential':
env = gym.make(args.environment, reward=ExpReward())
else:
raise RuntimeError('Reward function specified is not registered.')
# env wrappers (optionals)
if args.normalization:
env = NormalizeObservation(env)
if args.logger:
env = LoggerWrapper(env)
if args.multiobs:
env = MultiObsWrapper(env)
######################## TRAINING ########################
# env wrappers (optionals)
if args.normalization:
# We have to know what dictionary ranges to use
norm_range = None
env_type = args.environment.split('-')[2]
if env_type == 'datacenter':
range = RANGES_5ZONE
elif env_type == '5Zone':
range = RANGES_IW
elif env_type == 'IWMullion':
range = RANGES_DATACENTER
else:
raise NameError('env_type is not valid, check environment name')
env = NormalizeObservation(env, ranges=range)
if args.logger:
env = LoggerWrapper(env)
if args.multiobs:
env = MultiObsWrapper(env)
# Defining model(algorithm)
model = None
#--------------------------DQN---------------------------#
if args.algorithm == 'DQN':
model = DQN('MlpPolicy', env, verbose=1,
learning_rate=args.learning_rate,
buffer_size=args.buffer_size,
learning_starts=50000,
batch_size=32,
tau=args.tau,
gamma=args.gamma,
train_freq=4,
gradient_steps=1,
target_update_interval=10000,
exploration_fraction=.1,
exploration_initial_eps=1.0,
exploration_final_eps=.05,
max_grad_norm=args.max_grad_norm,
seed=args.seed,
tensorboard_log=args.tensorboard)
#--------------------------------------------------------#
#--------------------------DDPG--------------------------#
# The noise objects for DDPG
elif args.algorithm == 'DDPG':
if args.sigma:
n_actions = env.action_space.shape[-1]
action_noise = NormalActionNoise(mean=np.zeros(
n_actions), sigma=0.1 * np.ones(n_actions))
model = DDPG("MlpPolicy",
env,
action_noise=action_noise,
verbose=1,
seed=args.seed,
tensorboard_log=args.tensorboard)
#--------------------------------------------------------#
#--------------------------A2C---------------------------#
elif args.algorithm == 'A2C':
model = A2C('MlpPolicy', env, verbose=1,
learning_rate=args.learning_rate,
n_steps=args.n_steps,
gamma=args.gamma,
gae_lambda=args.gae_lambda,
ent_coef=args.ent_coef,
vf_coef=args.vf_coef,
max_grad_norm=args.max_grad_norm,
rms_prop_eps=args.rms_prop_eps,
seed=args.seed,
tensorboard_log=args.tensorboard)
#--------------------------------------------------------#
#--------------------------PPO---------------------------#
elif args.algorithm == 'PPO':
model = PPO('MlpPolicy', env, verbose=1,
learning_rate=args.learning_rate,
n_steps=args.n_steps,
batch_size=64,
n_epochs=10,
gamma=args.gamma,
gae_lambda=args.gae_lambda,
clip_range=.2,
ent_coef=0,
vf_coef=.5,
max_grad_norm=args.max_grad_norm,
seed=args.seed,
tensorboard_log=args.tensorboard)
#--------------------------------------------------------#
#--------------------------SAC---------------------------#
elif args.algorithm == 'SAC':
model = SAC(policy='MlpPolicy',
env=env,
seed=args.seed,
tensorboard_log=args.tensorboard)
#--------------------------------------------------------#
#-------------------------ERROR?-------------------------#
else:
raise RuntimeError('Algorithm specified is not registered.')
#--------------------------------------------------------#
# Calculating n_timesteps_episode for training
n_timesteps_episode = env.simulator._eplus_one_epi_len / \
env.simulator._eplus_run_stepsize
timesteps = args.episodes * n_timesteps_episode
# For callbacks processing
env_vec = DummyVecEnv([lambda: env])
# Using Callbacks for training
callbacks = []
# Set up Evaluation and saving best model
if args.evaluation:
eval_callback = LoggerEvalCallback(
env_vec,
best_model_save_path='best_model/' + name + '/',
log_path='best_model/' + name + '/',
eval_freq=n_timesteps_episode *
args.eval_freq,
deterministic=True,
render=False,
n_eval_episodes=args.eval_length)
callbacks.append(eval_callback)
# Set up tensorboard logger
if args.tensorboard:
log_callback = LoggerCallback(sinergym_logger=bool(args.logger))
callbacks.append(log_callback)
# lets change default dir for TensorboardFormatLogger only
tb_path = args.tensorboard + '/' + name
new_logger = configure(tb_path, ["tensorboard"])
model.set_logger(new_logger)
callback = CallbackList(callbacks)
# Training
model.learn(
total_timesteps=timesteps,
callback=callback,
log_interval=args.log_interval)
model.save(env.simulator._env_working_dir_parent + '/' + name)
# Store all results if remote_store flag is True
if args.remote_store:
# Initiate Google Cloud client
client = gcloud.init_storage_client()
# Code for send output and tensorboard to common resource here.
gcloud.upload_to_bucket(
client,
src_path=env.simulator._env_working_dir_parent,
dest_bucket_name='experiments-storage',
dest_path=name)
if args.tensorboard:
gcloud.upload_to_bucket(
client,
src_path=args.tensorboard + '/' + name + '/',
dest_bucket_name='experiments-storage',
dest_path=os.path.abspath(args.tensorboard).split('/')[-1] + '/' + name + '/')
if args.evaluation:
gcloud.upload_to_bucket(
client,
src_path='best_model/' + name + '/',
dest_bucket_name='experiments-storage',
dest_path='best_model/' + name + '/')
# gcloud.upload_to_bucket(
# client,
# src_path='mlruns/',
# dest_bucket_name='experiments-storage',
# dest_path='mlruns/')
# End mlflow run
mlflow.end_run()
# If it is a Google Cloud VM, shutdown remote machine when ends
if args.group_name:
token = gcloud.get_service_account_token()
gcloud.delete_instance_MIG_from_container(args.group_name, token)
The list of parameter is pretty large. Let’s see it:
--environmentor-env: Environment name you want to use (see Environments)--episodesor-ep: Number of episodes you want to train agent in simulation (Depending on environment episode length can be different)--algorithmor-alg: Algorithm you want to use to train (Currently, it is available PPO, A2C, DQN, DDPG and SAC)--rewardor-rw: Reward class you want to use for reward function. Currently, possible values are “linear” and “exponential”(see Rewards).--normalizationor-norm: Apply normalization wrapper to observations during training. If it isn’t specified wrapper will not be applied (see Wrappers).--multiobsor-mobs: Apply Multi-Observation wrapper to observations during training. If it isn’t specified wrapper will not be applied (see Wrappers).--loggeror-log: Apply Sinergym logger wrapper during training. If it isn’t specified wrapper will not be applied (see Wrappers and Logger).--tensorboardor-tens: This parameter will contain a path-file to allocate tensorboard training logs. If it isn’t specified this log will be deactivate (see DRL Logger).--evaluationor-eval: If it is specified, evaluation callback will be activate, else model evaluation will be deactivate during training (see Deep Reinforcement Learning Integration).--eval_freqor-evalf: Only if--evaluationflag has been written. Episode frequency for evaluation.--eval_lengthor-evall: Only if--evaluationflag has been written. Number of episodes for each evaluation.--log_intervalor-inter: This parameter is used forlearn()method in each algorithm. It is important specify a correct value.--seedor-sd: Seed for training, random components in process will be able to be recreated.--remote_storeor-sto: Determine if sinergym output will be sent to a common resource (Bucket), else will be allocate in remote container memory.--group_nameor-group: Added by cloud_manager.py automatically. It specify to which MIG the host instance belongs.algorithm hyperparameters: Execute
python DRL_battery --helpfor more information.
This script do the next:
Setting an appropriate name for the experiment. Following the next format:
<algorithm>-<environment_name>-episodes<episodes_int>-seed<seed_value>(<experiment_date>)Starting Mlflow track experiment with that name.
Log all MlFlow parameters (including sinergym.__version__).
Setting reward function specified in
--rewardparameter.Setting wrappers specified in environment.
Defining model algorithm using hyperparameters.
Calculate training timesteps using number of episodes.
Setting up evaluation callback if it has been specified.
Setting up Tensorboard logger callback if it has been specified.
Training with environment.
If
--remote_storehas been specified, saving all outputs in Google Cloud Bucket.Auto-delete remote container in Google Cloud Platform.
Containers permission to bucket storage output
As you see in sinergym template explained in 4. Create your VM or MIG, it is specified --scope, --service-account and --container-env. This aim to remote_store option in DRL_battery.py works correctly.
Those parameters provide each container with permissions to write in the bucket and manage Google Cloud Platform (auto instance remove function).
Container environment variables indicate zone, project_id and mlflow tracking server uri need it in Mlflow tracking server set up.
Remote Tensorboard log
In --tensorboard parameter we have to specify a local path in order to read this logs data in real-time.
However, we want to send this data to experiments-storage bucket created in Google Cloud Platform by cloud_manager.py process (see Executing API).
Hence, Tensorboard has added support to do this recently (#628).
You have to write gs://<bucket_name>/<tensorboard_log_path> in DRL_battery.py --tensorboard parameter directly.
Warning
In the case that gs URI isn’t recognized. Maybe is due to your tensorboard installation hasn’t got access your google account. Try gcloud auth application-default login command.
Visualize remote Tensorboard log in real-time
- You have two options:
Create a remote server with tensorboard service deployed.
Init that service in your local computer, reading from the bucket log, and access to the visualization in http://localhost:6006
The second options is enough since we can read from bucket when we need directly and shut down local service when we finish.
$ tensorboard --logdir gs://experiments-storage/tensorboard_log/
Mlflow tracking server set up
Mlflow tracking server can be set up into your google account in order to organize your own experiments (Mlflow). You can separate back-end (SQL database) from tracking server. In this way, you can shut down or delete server instance without loose your experiments run data, since SQL is always up. Let’s see how:
#!/bin/bash
# This scrip is used to build a mlflow server in Google Cloud, it is important
# to set up account previously.
# Please, visit our documentation here --> https://jajimer.github.io/sinergym/build/html/index.html
# Step 0 - Store all parameters
PROJECT_ID=$1
BUCKET_NAME=$2
ZONE=$3
REGION=${ZONE::-2}
DB_ROOT_PASSWORD=$4
MACHINE_TYPE=e2-medium
MLFLOW_IMAGE=kaysush/mlflow:1.14.1
CLOUD_SQL_PROXY_IMAGE=gcr.io/cloudsql-docker/gce-proxy:1.19.1
MYSQL_INSTANCE=${PROJECT_ID}:${REGION}:mlflow-backend
# Step 1 - Service account for mlflow service
echo "Creating Service account for mlflow service [mlflow-tracking-sa]..."
gcloud iam service-accounts create mlflow-tracking-sa --description="Service Account to run the MLFLow tracking server" --display-name="MLFlow tracking SA"
# Step 2 - Artifact used by mlflow to store all runs information
echo "Creating Back-end artifact bucket [$BUCKET_NAME]..."
gsutil mb gs://$BUCKET_NAME
# Step 3 - CLoud SQL, instance with SQL and "mlflow" database inner
echo "Creating sql instance with mlflow database [mlflow-backend]..."
gcloud sql instances create mlflow-backend --tier=db-f1-micro --region=${REGION} --root-password=${DB_ROOT_PASSWORD} --storage-type=SSD
gcloud sql databases create mlflow --instance=mlflow-backend
# Step 4 - IAM: Provisioning service account privileges in order to manipulate bucket and back-end
echo "Creating service account privileges to use Back-end [roles/cloudsql.editor]..."
gsutil iam ch "serviceAccount:mlflow-tracking-sa@${PROJECT_ID}.iam.gserviceaccount.com:roles/storage.admin" gs://${BUCKET_NAME}
gcloud projects add-iam-policy-binding ${PROJECT_ID} --member="serviceAccount:mlflow-tracking-sa@${PROJECT_ID}.iam.gserviceaccount.com" --role=roles/cloudsql.editor
# Step 5 - Creating start_mlflow_tracking.sh to initialize instance
echo "Creating start_mlflow_tracking.sh to initialize instance..."
cat <<EOF >./start_mlflow_tracking.sh
echo "Starting Cloud SQL Proxy'"
docker run -d --name mysql --net host -p 3306:3306 $CLOUD_SQL_PROXY_IMAGE /cloud_sql_proxy -instances $MYSQL_INSTANCE=tcp:0.0.0.0:3306
echo "Starting mlflow-tracking server"
docker run -d --name mlflow-tracking --net host -p 5000:5000 $MLFLOW_IMAGE mlflow server --backend-store-uri mysql+pymysql://root:${DB_ROOT_PASSWORD}@localhost/mlflow --default-artifact-root gs://${BUCKET_NAME}/mlflow_artifacts/ --host 0.0.0.0
echo "Altering IPTables"
iptables -A INPUT -p tcp --dport 5000 -j ACCEPT
EOF
# Step 6 - Uploading start script and deleting from local
echo "Uploading start_mlflow_tracking.sh at gs://${BUCKET_NAME}/scripts/start_mlflow_tracking.sh..."
gsutil cp ./start_mlflow_tracking.sh gs://${BUCKET_NAME}/scripts/start_mlflow_tracking.sh
echo "Deleting temporal local script [start_mlflow_tracking.sh]"
rm ./start_mlflow_tracking.sh
#Step 7 - creating static external ip for mlflow server
echo "Creating static external ip for mlflow-tracking-server [mlflow-ip]"
gcloud compute addresses create mlflow-ip \
--region europe-west1
# Step 8 - Compute Instance
echo "Deploying remote server [mlflow-tracking-server]..."
gcloud compute --project=$PROJECT_ID instances create mlflow-tracking-server \
--zone=$ZONE \
--machine-type=$MACHINE_TYPE \
--subnet=default \
--network-tier=PREMIUM \
--metadata=startup-script-url=gs://${BUCKET_NAME}/scripts/start_mlflow_tracking.sh \
--maintenance-policy=MIGRATE \
--service-account=mlflow-tracking-sa@${PROJECT_ID}.iam.gserviceaccount.com \
--scopes=https://www.googleapis.com/auth/cloud-platform \
--tags=mlflow-tracking-server \
--image=cos-77-12371-1109-0 \
--image-project=cos-cloud \
--boot-disk-size=10GB \
--boot-disk-type=pd-balanced \
--boot-disk-device-name=mlflow-tracking-server \
--no-shielded-secure-boot \
--shielded-vtpm \
--shielded-integrity-monitoring \
--reservation-affinity=any \
--address $(gcloud compute addresses describe mlflow-ip --format='get(address)')
# Step 8 - Firewall
echo "Creating firewall rules [allow-mlflow-tracking]..."
gcloud compute firewall-rules create allow-mlflow-tracking --network default --priority 1000 --direction ingress --action allow --target-tags mlflow-tracking-server --source-ranges 0.0.0.0/0 --rules tcp:5000 --enable-logging
This bash script define all the process to configure this functionality automatically. (Once you execute it you don’t have to use this script anymore). The arguments it needs are: PROJECT_ID, BUCKET_NAME, ZONE and DB_ROOT_PASSWORD.
This script do the next for you:
Creating Service account for mlflow service [mlflow-tracking-sa].
Creating Back-end artifact bucket.
Creating sql instance with root password specified in argument 4.
Creating mlflow database inner SQL instance.
Creating service account privileges to use Back-end [roles/cloudsql.editor]
Generating an automatic script called start_mlflow_tracking.sh and sending to gs://<BUCKET_NAME>/scripts/
Deleting local start_mlflow_tracking.sh file.
Creating static external ip for mlflow-tracking-server
Deploying remote server [mlflow-tracking-server]
Step 8 is very important, this allows you to delete server instance and create again when you need it without redefining server ip in sinergym-template for remote container experiments. Notice that server instance creation use service account for mlflow, with this configuration mlflow can read from SQL server. In 4. Create your VM or MIG it is specified MLFLOW_TRACKING_URI container environment variable using that external static ip.
Warning
It is important execute this script before create sinergym-template instances in order to anotate mlflow-server-ip.
Note
If you want to change any backend configuration, you can change any parameter of the script bellow.
Google Cloud Alerts
Google Cloud Platform include functionality in order to trigger some events and generate alerts in consequence. Then, a trigger has been created in our gcloud project which aim to advertise when an experiment has finished. This alert can be captured in several ways (slack, sms, email, etc). If you want to do the same, please, check Google Cloud Alerts documentation here.