Deep Reinforcement Learning Integration
Sinergym integrates some facilities in order to use Deep Reinforcement Learning algorithms provided by Stable Baselines 3. Current algorithms checked by Sinergym are:
Stable Baselines 3: |
|||
Algorithm |
Discrete |
Continuous |
Type |
PPO |
YES |
YES |
OnPolicyAlgorithm |
A2C |
YES |
YES |
OnPolicyAlgorithm |
DQN |
YES |
NO |
OffPolicyAlgorithm |
DDPG |
NO |
YES |
OffPolicyAlgorithm |
SAC |
NO |
YES |
OffPolicyAlgorithm |
Type column has been specified due to its importance about Stable Baselines callback functionality.
DRL Logger
Callbacks are a set of functions that will be called at given stages of the training procedure. You can use callbacks to access internal state of the RL model during training. It allows one to do monitoring, auto saving, model manipulation, progress bars, …
This structure allows to custom our own logger for DRL executions. Our objective is to log all information about our custom environment specifically.
Therefore, sinergym/sinergym/utils/callbacks.py has been created with this proposal.
Each algorithm has its own differences about how information is extracted which is why its implementation. LoggerCallback can deal with those subtleties.
class LoggerCallback(BaseCallback):
"""Custom callback for plotting additional values in tensorboard.
:param sinergym_logger: Boolean, indicate if CSVLogger inner Sinergym will be activated or not.
:param ep_rewards: Here will be stored all rewards during episode.
:param ep_powers: Here will be stored all consumption data during episode.
:param ep_term_comfort: Here will be stored all comfort terms (reward component) during episode.
:param ep_term_energy: Here will be stored all energy terms (reward component) during episode.
:param num_comfort_violation: Number of timesteps in which comfort has been violated.
:param ep_timesteps: Each timestep during an episode, this value increment 1.
"""
def __init__(self, sinergym_logger=False, verbose=0):
super(LoggerCallback, self).__init__(verbose)
self.sinergym_logger = sinergym_logger
self.ep_rewards = []
self.ep_powers = []
self.ep_term_comfort = []
self.ep_term_energy = []
self.num_comfort_violation = 0
self.ep_timesteps = 0
def _on_training_start(self):
# sinergym logger
if is_wrapped(self.training_env, LoggerWrapper):
if self.sinergym_logger:
self.training_env.env_method('activate_logger')
else:
self.training_env.env_method('deactivate_logger')
# record method depending on the type of algorithm
if 'OnPolicyAlgorithm' in self.globals.keys():
self.record = self.logger.record
elif 'OffPolicyAlgorithm' in self.globals.keys():
self.record = self.logger.record_mean
else:
raise KeyError
def _on_step(self) -> bool:
info = self.locals['infos'][-1]
# OBSERVATION
variables = self.training_env.get_attr('variables')[0]['observation']
# log normalized and original values
if self.training_env.env_is_wrapped(
wrapper_class=NormalizeObservation)[0]:
obs_normalized = self.locals['new_obs'][-1]
obs = self.training_env.env_method('get_unwrapped_obs')[-1]
for i, variable in enumerate(variables):
self.record(
'normalized_observation/' + variable, obs_normalized[i])
self.record(
'observation/' + variable, obs[i])
# Only original values
else:
obs = self.locals['new_obs'][-1]
for i, variable in enumerate(variables):
self.record(
'observation/' + variable, obs[i])
# ACTION
variables = self.training_env.get_attr('variables')[0]['action']
action = None
# sinergym action received inner its own setpoints range
action_ = info['action_']
try:
# network output clipped with gym action space
action = self.locals['clipped_actions'][-1]
except KeyError:
try:
action = self.locals['action'][-1]
except KeyError:
print('Algorithm action key in locals dict unknown')
if self.training_env.get_attr('flag_discrete')[0]:
action = self.training_env.get_attr('action_mapping')[0][action]
for i, variable in enumerate(variables):
if action is not None:
self.record(
'action/' + variable, action[i])
self.record(
'action_simulation/' + variable, action_[i])
# Store episode data
try:
self.ep_rewards.append(self.locals['rewards'][-1])
except KeyError:
try:
self.ep_rewards.append(self.locals['reward'][-1])
except KeyError:
print('Algorithm reward key in locals dict unknown')
self.ep_powers.append(info['total_power'])
self.ep_term_comfort.append(info['comfort_penalty'])
self.ep_term_energy.append(info['total_power_no_units'])
if(info['comfort_penalty'] != 0):
self.num_comfort_violation += 1
self.ep_timesteps += 1
# If episode ends, store summary of episode and reset
try:
done = self.locals['dones'][-1]
except KeyError:
try:
done = self.locals['done'][-1]
except KeyError:
print('Algorithm done key in locals dict unknown')
if done:
# store last episode metrics
self.episode_metrics = {}
self.episode_metrics['ep_length'] = self.ep_timesteps
self.episode_metrics['cumulative_reward'] = np.sum(
self.ep_rewards)
self.episode_metrics['mean_reward'] = np.mean(self.ep_rewards)
self.episode_metrics['mean_power'] = np.mean(self.ep_powers)
self.episode_metrics['cumulative_power'] = np.sum(self.ep_powers)
self.episode_metrics['mean_comfort_penalty'] = np.mean(
self.ep_term_comfort)
self.episode_metrics['cumulative_comfort_penalty'] = np.sum(
self.ep_term_comfort)
self.episode_metrics['mean_power_penalty'] = np.mean(
self.ep_term_energy)
self.episode_metrics['cumulative_power_penalty'] = np.sum(
self.ep_term_energy)
try:
self.episode_metrics['comfort_violation_time(%)'] = self.num_comfort_violation / \
self.ep_timesteps * 100
except ZeroDivisionError:
self.episode_metrics['comfort_violation_time(%)'] = np.nan
# reset episode info
self.ep_rewards = []
self.ep_powers = []
self.ep_term_comfort = []
self.ep_term_energy = []
self.ep_timesteps = 0
self.num_comfort_violation = 0
# During first episode, as it not finished, it shouldn't be recording
if hasattr(self, 'episode_metrics'):
for key, metric in self.episode_metrics.items():
self.logger.record(
'episode/' + key, metric)
return True
def on_training_end(self):
if is_wrapped(self.training_env, LoggerWrapper):
self.training_env.env_method('activate_logger')
Note
You can specify if you want Sinergym logger (see Logger) to record simulation interactions during training at the same time using sinergym_logger attribute in constructor.
This callback derives BaseCallback from Stable Baselines 3 while BaseCallBack uses Tensorboard on the background at the same time.
With Tensorboard, it’s possible to visualize all DRL training in real time and compare between different executions. This is an example:
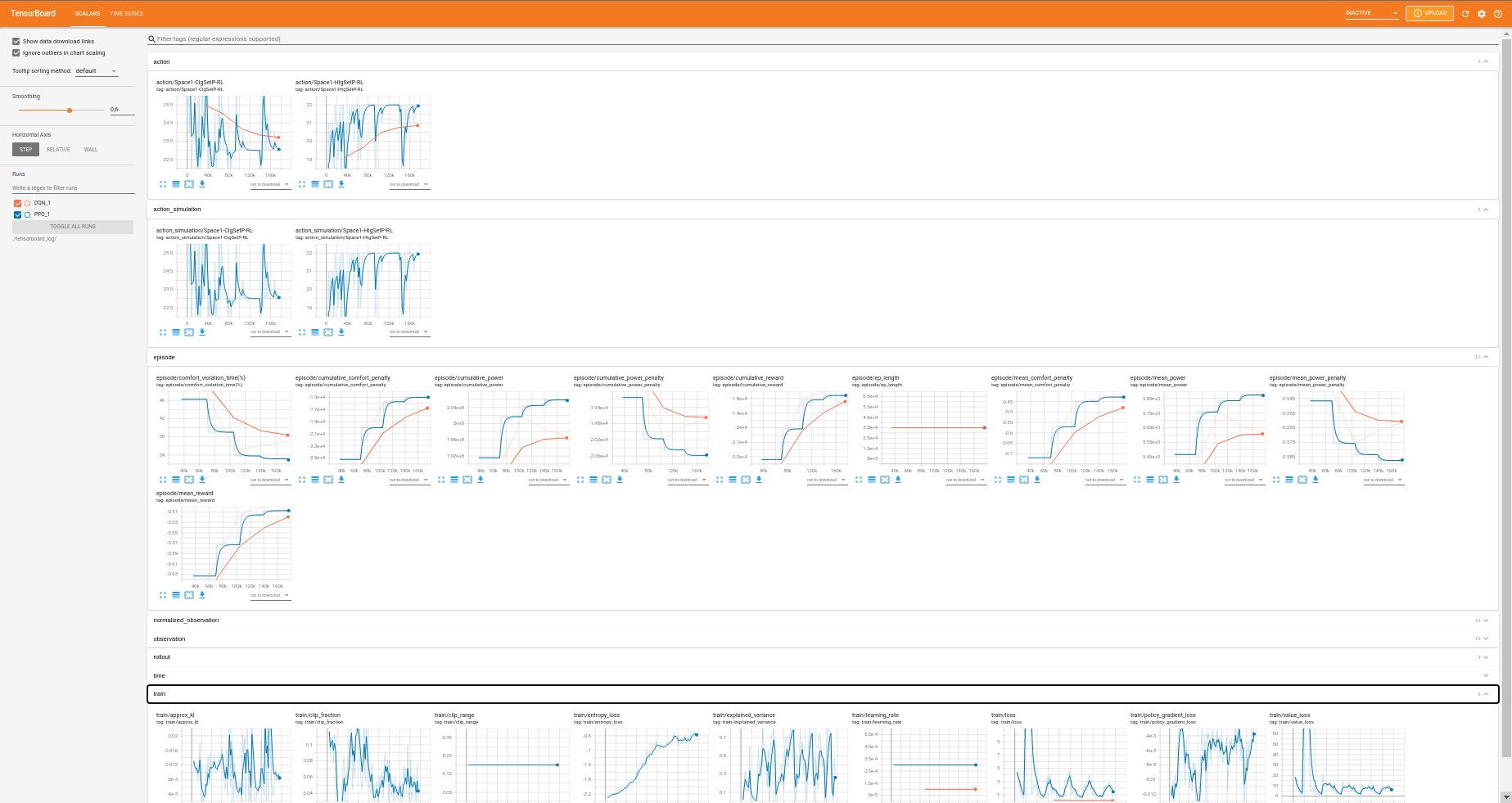
There are tables which are in some algorithms and not in others and vice versa. It is important the difference between OnPolicyAlgorithms and OffPolicyAlgorithms:
OnPolicyAlgorithms can be recorded each timestep, we can set a
log_intervalin learn process in order to specify the step frequency log.OffPolicyAlgorithms can be recorded each episode. Consequently,
log_intervalin learn process is used to specify the episode frequency log and not step frequency. Some features like actions and observations are set up in each timestep. Thus, Off Policy Algorithms record a mean value of whole episode values instead of values steps by steps (seeLoggerCallbackclass implementation).
Tensorboard structure
The main structure for Sinergym with Tensorboard is:
action: This section has action values during training. When algorithm is On Policy will appear action_simulation too. This is because algorithms in continuous environments has their own output and clipped with gym action space. Then, this output is parse to simulation action space (See Observation/action spaces).
- episode: Here is stored all information about entires episodes. It is equivalent to progress.csv in Sinergym logger (see Sinergym Output format):
comfort_violation_time(%): Percentage of time in episode simulation in which temperature has been out of bound comfort temperature ranges.
cumulative_comfort_penalty: Sum of comfort penalties (reward component) during whole episode.
cumulative_power: Sum of power consumption during whole episode.
cumulative_power_penalty: Sum of power penalties (reward component) during whole episode.
cumulative_reward: Sum of reward during whole episode.
ep_length: Timesteps executed in each episode.
mean_comfort_penalty: Mean comfort penalty per step in episode.
mean_power: Mean power consumption per step in episode.
mean_power_penalty: Mean power penalty per step in episode.
mean_reward: Mean reward obtained per step in episode.
observation: Here is recorded all observation values during simulation. This values depends on the environment which is being simulated (see Output format).
normalized_observation (optional): This section appear only when environment has been wrapped with normalization (see Wrappers). The model will train with this normalized values and they will be recorded both; original observation and normalized observation.
rollout: Algorithm metrics in Stable Baselines by default. For example, DQN has exploration_rate and this value doesn’t appear in other algorithms.
time: Monitoring time of execution.
train: Record specific neural network information for each algorithm, provided by Stable baselines as well as rollout.
Note
Evaluation of models can be recorded too, adding EvalLoggerCallback to model learn method.
How use
You can try your own experiments and benefit from this functionality. sinergym/examples/DRL_usage.py is a example code to use it.
The most important information you must keep in mind when you try your own experiments are:
Model is constructed with a algorithm constructor. Each algorithm can use its particular parameters.
If you wrapper environment with normalization, models will train with those normalized values.
Callbacks can be concatenated in a
CallbackListinstance from Stable Baselines 3.Neural network will not train until you execute
model.learn()method. Here is where you specify traintimesteps,callbacksandlog_intervalas we commented in type algorithms (On and Off Policy).DRL_usage.pyrequires some extra arguments to being executed like-envand-ep.
Code example:
import gym
import argparse
import mlflow
from sinergym.utils.callbacks import LoggerCallback, LoggerEvalCallback
from sinergym.utils.wrappers import NormalizeObservation
from stable_baselines3.common.noise import NormalActionNoise, OrnsteinUhlenbeckActionNoise
from stable_baselines3 import A2C, DDPG, DQN, PPO, SAC
from stable_baselines3.common.callbacks import EvalCallback, BaseCallback, CallbackList
from stable_baselines3.common.vec_env import DummyVecEnv
parser = argparse.ArgumentParser()
parser.add_argument('--environment', '-env', type=str, default=None)
parser.add_argument('--episodes', '-ep', type=int, default=1)
parser.add_argument('--learning_rate', '-lr', type=float, default=.0007)
parser.add_argument('--n_steps', '-n', type=int, default=5)
parser.add_argument('--gamma', '-g', type=float, default=.99)
parser.add_argument('--gae_lambda', '-gl', type=float, default=1.0)
parser.add_argument('--ent_coef', '-ec', type=float, default=0)
parser.add_argument('--vf_coef', '-v', type=float, default=.5)
parser.add_argument('--max_grad_norm', '-m', type=float, default=.5)
parser.add_argument('--rms_prop_eps', '-rms', type=float, default=1e-05)
args = parser.parse_args()
# experiment ID
environment = args.environment
n_episodes = args.episodes
name = 'A2C-' + environment + '-' + str(n_episodes) + '-episodes'
with mlflow.start_run(run_name=name):
mlflow.log_param('env', environment)
mlflow.log_param('episodes', n_episodes)
mlflow.log_param('learning_rate', args.learning_rate)
mlflow.log_param('n_steps', args.n_steps)
mlflow.log_param('gamma', args.gamma)
mlflow.log_param('gae_lambda', args.gae_lambda)
mlflow.log_param('ent_coef', args.ent_coef)
mlflow.log_param('vf_coef', args.vf_coef)
mlflow.log_param('max_grad_norm', args.max_grad_norm)
mlflow.log_param('rms_prop_eps', args.rms_prop_eps)
env = gym.make(environment)
env = NormalizeObservation(env)
#### TRAINING ####
# Build model
model = A2C('MlpPolicy', env, verbose=1,
learning_rate=args.learning_rate,
n_steps=args.n_steps,
gamma=args.gamma,
gae_lambda=args.gae_lambda,
ent_coef=args.ent_coef,
vf_coef=args.vf_coef,
max_grad_norm=args.max_grad_norm,
rms_prop_eps=args.rms_prop_eps,
tensorboard_log='./tensorboard_log/')
n_timesteps_episode = env.simulator._eplus_one_epi_len / \
env.simulator._eplus_run_stepsize
timesteps = n_episodes * n_timesteps_episode
env = DummyVecEnv([lambda: env])
# Callbacks
freq = 2 # evaluate every N episodes
eval_callback = LoggerEvalCallback(env, best_model_save_path='./best_models/' + name + '/',
log_path='./best_models/' + name + '/', eval_freq=n_timesteps_episode * freq,
deterministic=True, render=False, n_eval_episodes=1)
log_callback = LoggerCallback(sinergym_logger=False)
callback = CallbackList([log_callback, eval_callback])
# Training
model.learn(total_timesteps=timesteps, callback=callback, log_interval=100)
Mlflow
As you have been able to see in usage examples, it is using Mlflow in order to tracking experiments and recorded them methodically. It is recommended to use it. You can start a local server with information stored during the battery of experiments such as initial and ending date of execution, hyperparameters, duration, etc. Here is an example:
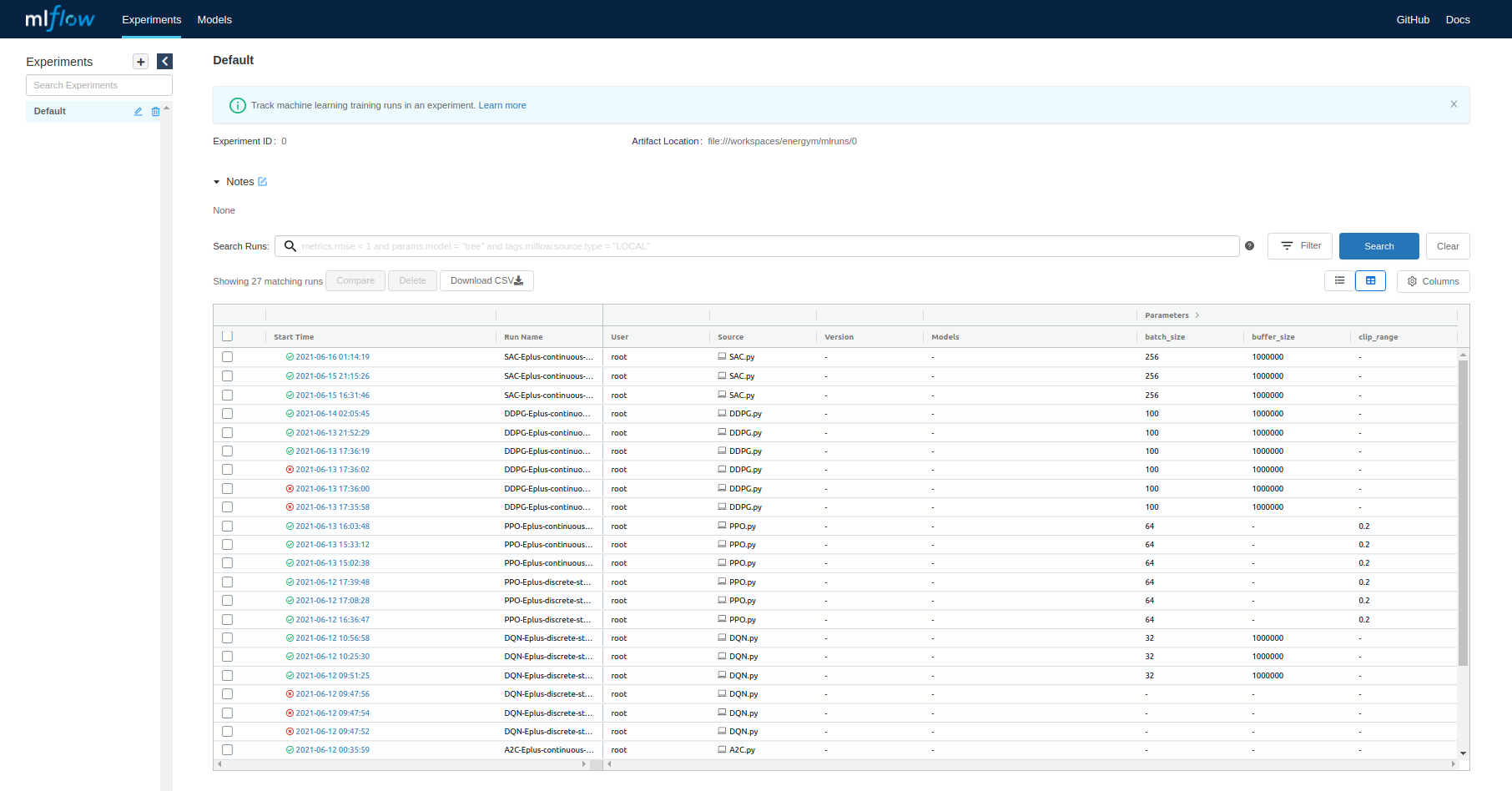
Note
For information about how use Tensorboard and Mlflow with a Cloud Computing paradigm, see Remote Tensorboard log and Mlflow tracking server set up
Note
This is a work in progress project. Compatibility with others algorithms is being planned for the future!