11. Deep Reinforcement Learning Integration
Sinergym integrates some facilities in order to use Deep Reinforcement Learning algorithms provided by Stable Baselines 3. Current algorithms checked by Sinergym are:
Stable Baselines 3: |
|||
Algorithm |
Discrete |
Continuous |
Type |
PPO |
YES |
YES |
OnPolicyAlgorithm |
A2C |
YES |
YES |
OnPolicyAlgorithm |
DQN |
YES |
NO |
OffPolicyAlgorithm |
DDPG |
NO |
YES |
OffPolicyAlgorithm |
SAC |
NO |
YES |
OffPolicyAlgorithm |
TD3 |
NO |
YES |
OffPolicyAlgorithm |
For that purpose, we are going to refine and develop Callbacks which are a set of functions that will be called at given stages of the training procedure. You can use callbacks to access internal state of the RL model during training. It allows one to do monitoring, auto saving, model manipulation, progress bars, … Our callbacks inherit from Stable Baselines 3 and are available in sinergym/sinergym/utils/callbacks.py.
Type column has been specified due to its importance about
Stable Baselines callback functionality.
11.1. DRL Callback Logger
A callback allows to custom our own logger for DRL Sinergym executions. Our objective is to log all information about our custom environment specifically in real-time. Each algorithm has its own differences about how information is extracted which is why its implementation.
Note
You can specify if you want Sinergym logger (see Logger) to record
simulation interactions during training at the same time using
sinergym_logger attribute in constructor.
The LoggerCallback inherits from Stable Baselines 3 BaseCallback and
uses Weights&Biases (wandb) in the background in order to host
all information extracted. With wandb, it’s possible to track and visualize all DRL
training in real time, register hyperparameters and details of each execution, save artifacts
such as models and sinergym output, and compare between different executions. This is an example:
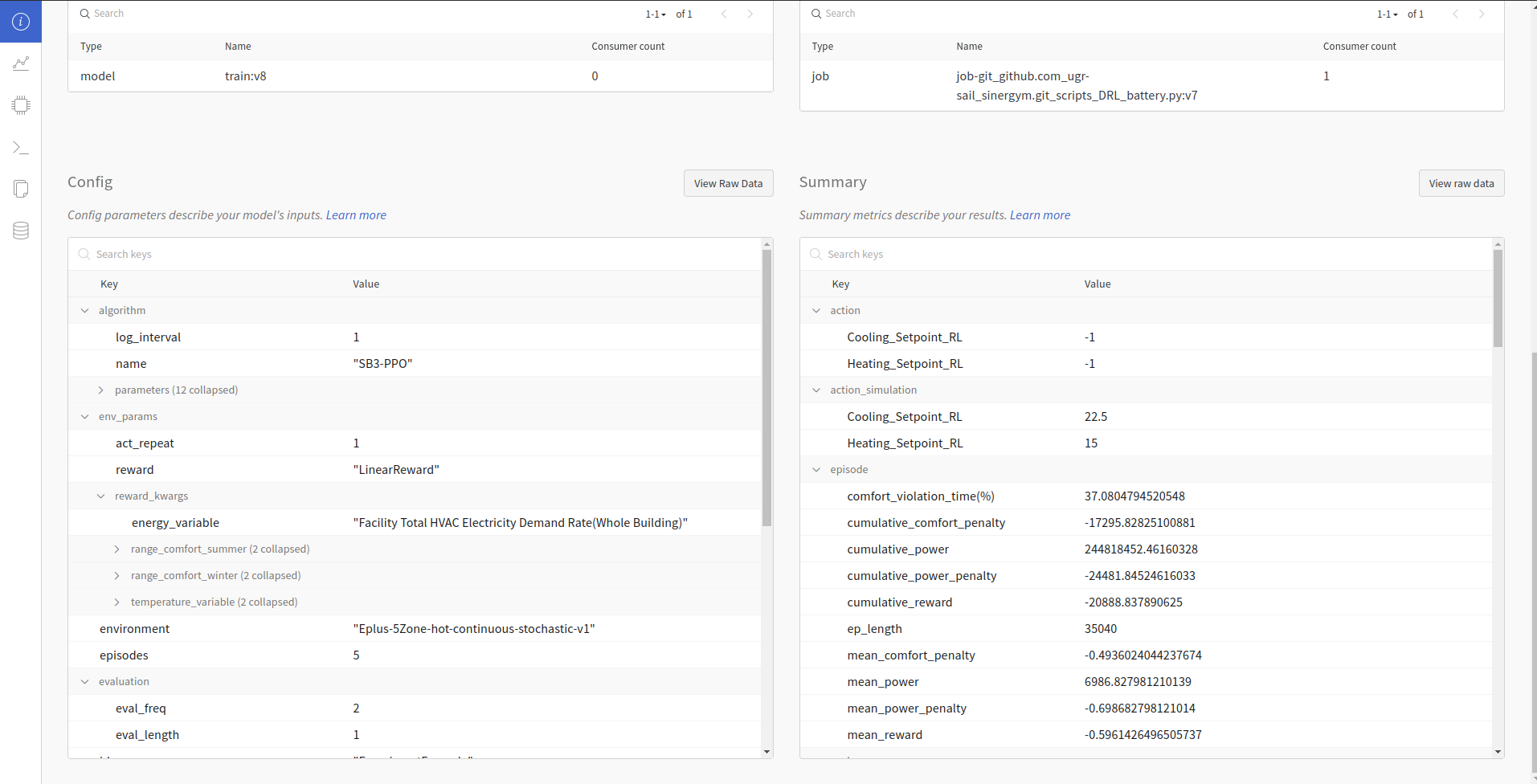
Hyperparameter and summary registration:
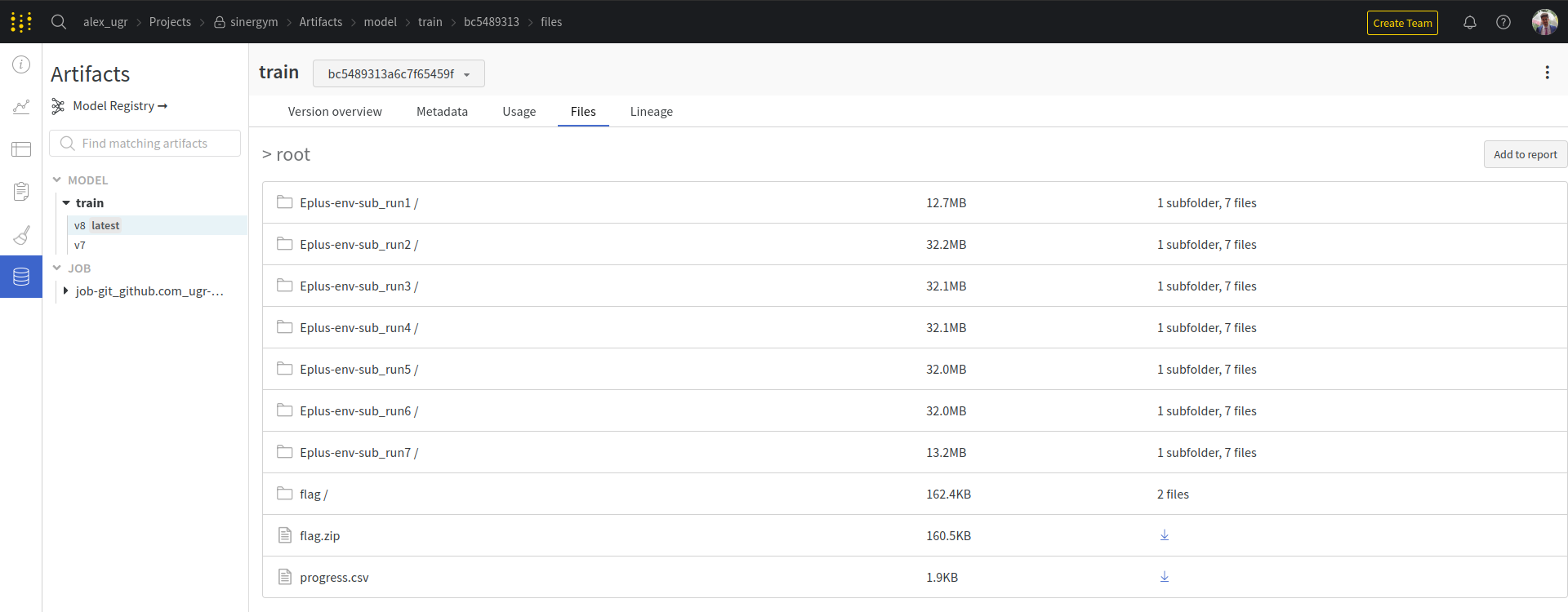
Artifacts registered (if evaluation is enabled, best model is registered too):
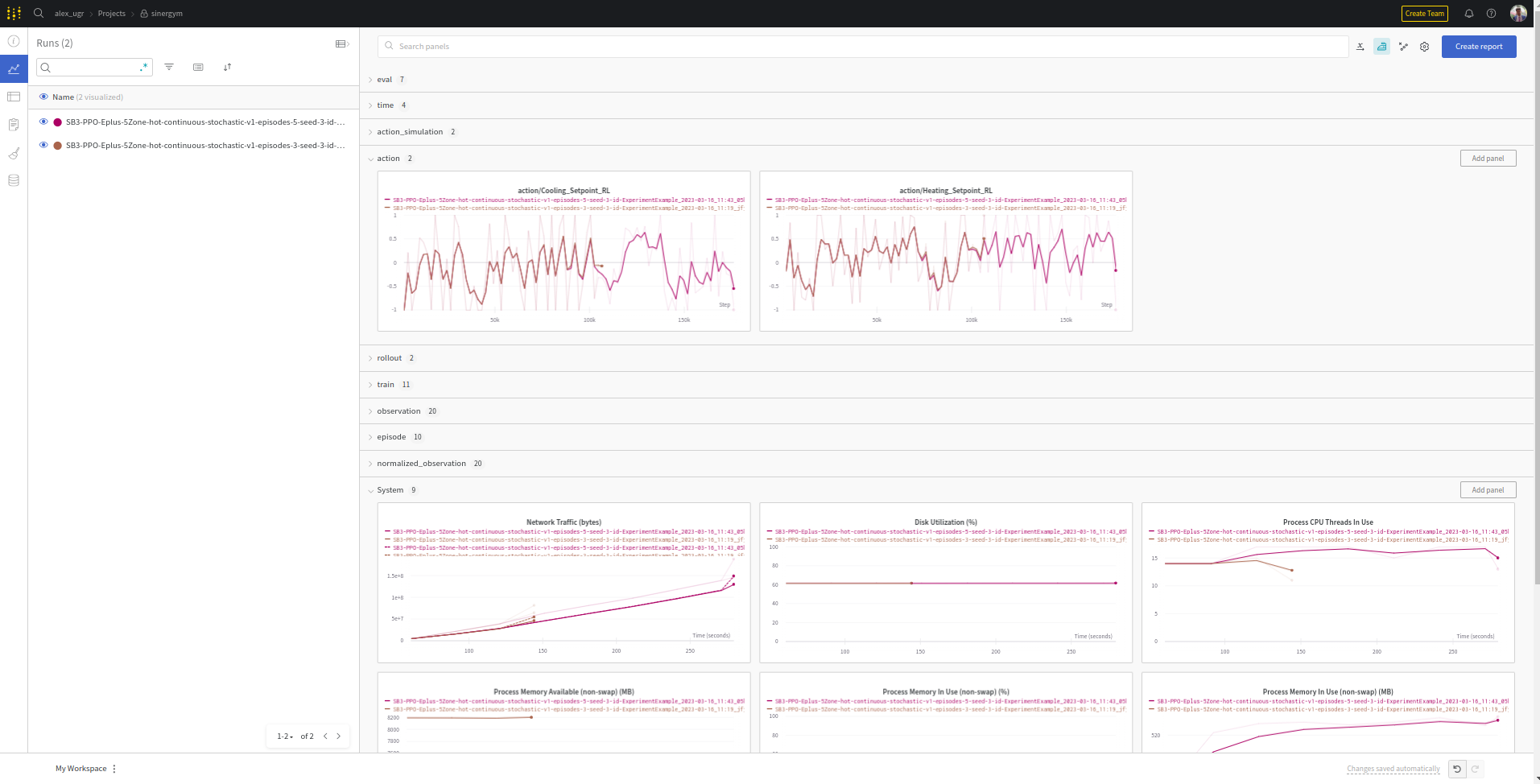
Metrics visualization in real time:
There are tables which are in some algorithms and not in others and vice versa.
It is important the difference between OnPolicyAlgorithms and OffPolicyAlgorithms:
OnPolicyAlgorithms can be recorded each timestep, we can set a
log_intervalin learn process in order to specify the step frequency log.OffPolicyAlgorithms can be recorded each episode. Consequently,
log_intervalin learn process is used to specify the episode frequency log and not step frequency. Some features like actions and observations are set up in each timestep. Thus, Off Policy Algorithms record a mean value of whole episode values instead of values steps by steps (seeLoggerCallbackclass implementation).
11.2. Evaluation Callback
A callback has also been refined for the evaluation of the model versions obtained during the training process with Sinergym, so that it stores the best model obtained (not the one resulting at the end of the training).
Its name is LoggerEvalCallback and it inherits from Stable Baselines 3 EvalCallback.
The main feature added is that the model evaluation is logged in a particular section in
wandb too for the concrete metrics of the building model.
We have to define in LoggerEvalCallback construction how many training episodes we want
the evaluation process to take place. On the other hand, we have to define how many episodes
are going to occupy each of the evaluations to be performed.
The more episodes, the more accurate the averages of the reward-based indicators will be, and, therefore, the more faithful it will be to reality in terms of how good the current model is turning out to be. However, it will take more time.
It calculates timestep and episode average for power consumption, comfort penalty and power penalty. On the other hand, it calculates comfort violation percentage in episodes too. Currently, only mean reward is taken into account to decide when a model is better.
11.3. Weights and Biases structure
The main structure for Sinergym with wandb is:
action: This section has action values during training. When algorithm is On Policy, it will appear action_simulation too. This is because algorithms in continuous environments has their own output and clipped with gymnasium action space. Then, this output is parse to simulation action space (See Observation/action spaces note box).
episode: Here is stored all information about entire episodes. It is equivalent to
progress.csvin Sinergym logger (see Sinergym Output format section):comfort_violation_time(%): Percentage of time in episode simulation in which temperature has been out of bound comfort temperature ranges.
cumulative_comfort_penalty: Sum of comfort penalties (reward component) during whole episode.
cumulative_power: Sum of power consumption during whole episode.
cumulative_power_penalty: Sum of power penalties (reward component) during whole episode.
cumulative_reward: Sum of reward during whole episode.
ep_length: Timesteps executed in each episode.
mean_comfort_penalty: Mean comfort penalty per step in episode.
mean_power: Mean power consumption per step in episode.
mean_power_penalty: Mean power penalty per step in episode.
mean_reward: Mean reward obtained per step in episode.
observation: Here is recorded all observation values during simulation. This values depends on the environment which is being simulated (see Observation/action spaces section).
normalized_observation (optional): This section appear only when environment has been wrapped with normalization (see Wrappers section). The model will train with this normalized values and they will be recorded both; original observation and normalized observation.
rollout: Algorithm metrics in Stable Baselines by default. For example, DQN has
exploration_rateand this value doesn’t appear in other algorithms.time: Monitoring time of execution.
train: Record specific neural network information for each algorithm, provided by Stable baselines as well as rollout.
Note
Evaluation of models can be recorded too, adding EvalLoggerCallback
to model learn method.
11.4. How to use
For more information about how to use it with cloud computing, visit Sinergym with Google Cloud
11.4.1. Train a model
You can try your own experiments and benefit from this functionality.
sinergym/scripts/DRL_battery.py
is a script to help you to do it. You can use DRL_battery.py directly from
your local computer or using Google Cloud Platform.
The most important information you must keep in mind when you try your own experiments are:
Model is constructed with a algorithm constructor. Each algorithm can use its particular parameters.
If you wrapper environment with normalization, models will train with those normalized values.
Callbacks can be concatenated in a
CallbackListinstance from Stable Baselines 3.Neural network will not train until you execute
model.learn()method. Here is where you specify traintimesteps,callbacksandlog_intervalas we commented in type algorithms (On and Off Policy).You can execute Curriculum Learning, you only have to add model field with a valid model path, this script will load the model and execute to train.
DRL_battery.py has a unique parameter to be able to execute it; -conf.
This parameter is a str to indicate the JSON file in which there are allocated
all information about the experiment you want to execute. You can see the
JSON structure example in sinergym/scripts/DRL_battery_example.json:
The obligatory parameters are: environment, episodes, algorithm (and parameters of the algorithm which don’t have default values).
The optional parameters are: All environment parameters (if it is specified will be overwrite the default environment value), seed, model to load (before training), experiment ID, wrappers to use (respecting the order), training evaluation, wandb functionality and cloud options.
The name of the fields must be like in example mentioned. Otherwise, the experiment will return an error.
This script do the next:
Setting an appropriate name for the experiment. Following the next format:
<algorithm>-<environment_name>-episodes<episodes_int>-seed<seed_value>(<experiment_date>)Starting WandB track experiment with that name (if configured in JSON), it will create an local path (./wandb) too.
Log all parameters allocated in JSON configuration (including sinergym.__version__ and python version).
Setting env with parameters overwritten in case of establishing them.
Setting wrappers specified in JSON.
Defining model algorithm using hyperparameters defined.
Calculate training timesteps using number of episodes.
Setting up evaluation callback if it has been specified.
Setting up WandB logger callback if it has been specified.
Training with environment.
If remote store has been specified, saving all outputs in Google Cloud Bucket. If wandb has been specified, saving all outputs in wandb run artifact.
Auto-delete remote container in Google Cloud Platform when parameter auto-delete has been specified.
11.4.2. Load a trained model
You can try load a previous trained model and evaluate or execute it.
sinergym/scripts/load_agent.py
is a script to help you to do it. You can use load_agent.py directly from
your local computer or using Google Cloud Platform.
load_agent.py has a unique parameter to be able to execute it; -conf.
This parameter is a str to indicate the JSON file in which there are allocated
all information about the evaluation you want to execute. You can see the
JSON structure example in sinergym/scripts/load_agent_example.json:
The obligatory parameters are: environment, episodes, algorithm (only algorithm name is necessary) and model to load.
The optional parameters are: All environment parameters (if it is specified will be overwrite the default environment value), experiment ID, wrappers to use (respecting the order), wandb functionality and cloud options.
This script loads the model. Once the model is loaded, it predicts the actions from the states during the agreed episodes. The information is collected and sent to a remote storage if it is indicated (such as WandB), otherwise it is stored in local memory.
Note
This is a work in progress project. Direct support with others algorithms is being planned for the future!