9. Wrappers
Sinergym has several wrappers in order to add some functionality in the environment that it doesn’t have by default. The code can be found in sinergym/sinergym/utils/wrappers.py. You can implement your own wrappers inheriting from gym.Wrapper or some of its variants, see Gymnasium documentation.
9.1. MultiObjectiveReward
Environment step will return a vector reward (selected elements in wrapper constructor, one for each objective) instead of a traditional scalar value. See #301.
9.2. PreviousObservationWrapper
Wrapper to add observation values from previous timestep to current environment observation. It is possible to select the variables you want to track its previous observation values.
9.3. DatetimeWrapper
Wrapper to substitute day_of_month value by is_weekend flag, and hour and month by sin and cos values.
Observation space is updated automatically.
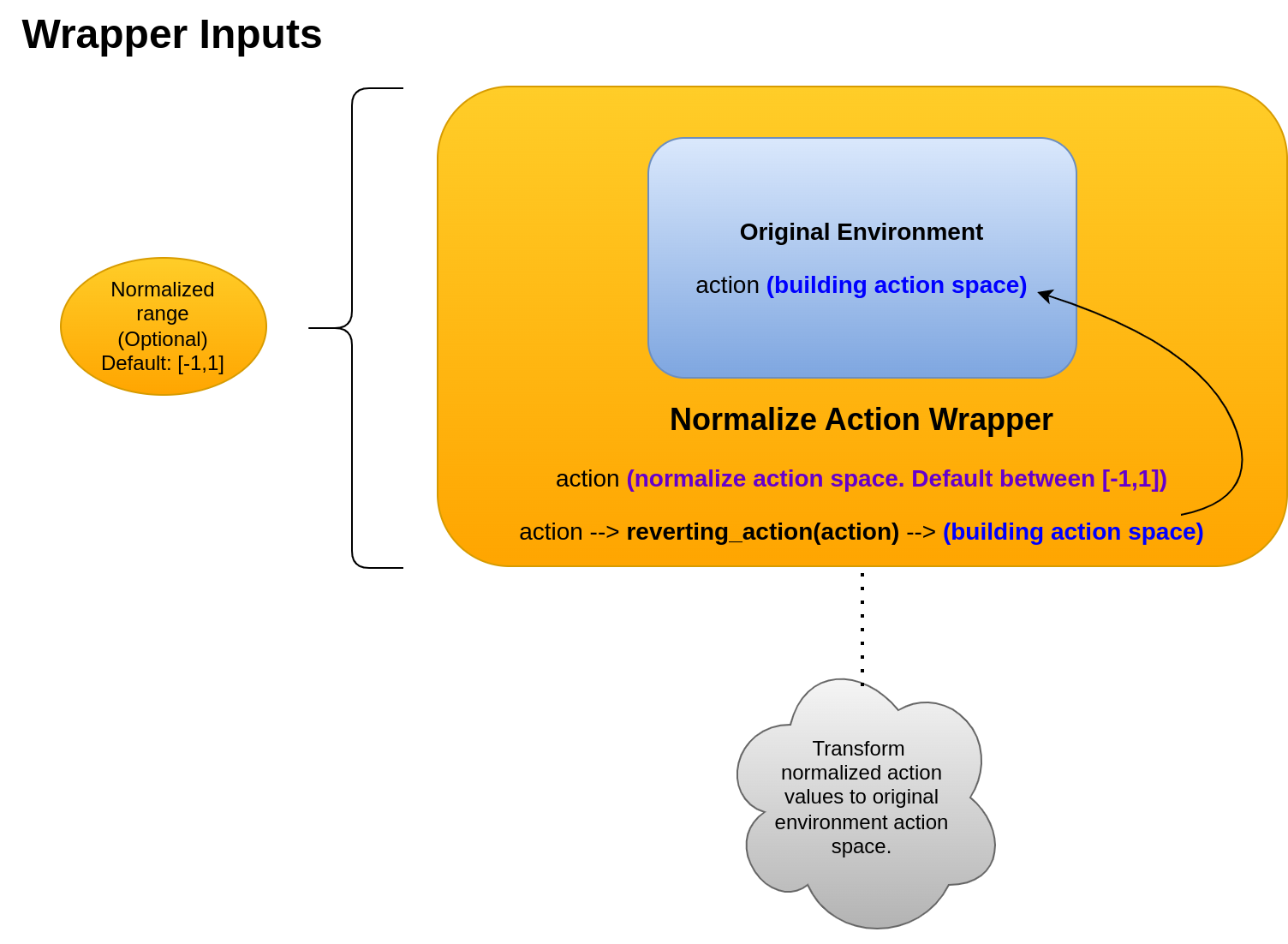
9.4. NormalizeAction
Wrapper to apply normalization in action space. It is very useful in DRL algorithms such as some of them only works with normalized values correctly, making environments more generic in DRL solutions.
By default, the normalization is applied in the range [-1,1]. However, other range can be specified when wrapper
is instantiated.
Sinergym parse these values to real action space defined in original environment internally before to send it to EnergyPlus Simulator by the API middleware.
Important
The method in charge of parse this values from [-1,1] to real action space if it is required is
called reverting_action(action) in the wrapper class.
We always recommend to use the normalization in action space for DRL solutions, since this space is
compatible with all algorithms. However, if you are implementing your own rule-based controller
and working with real action values, for example, you don’t must to apply this wrapper.
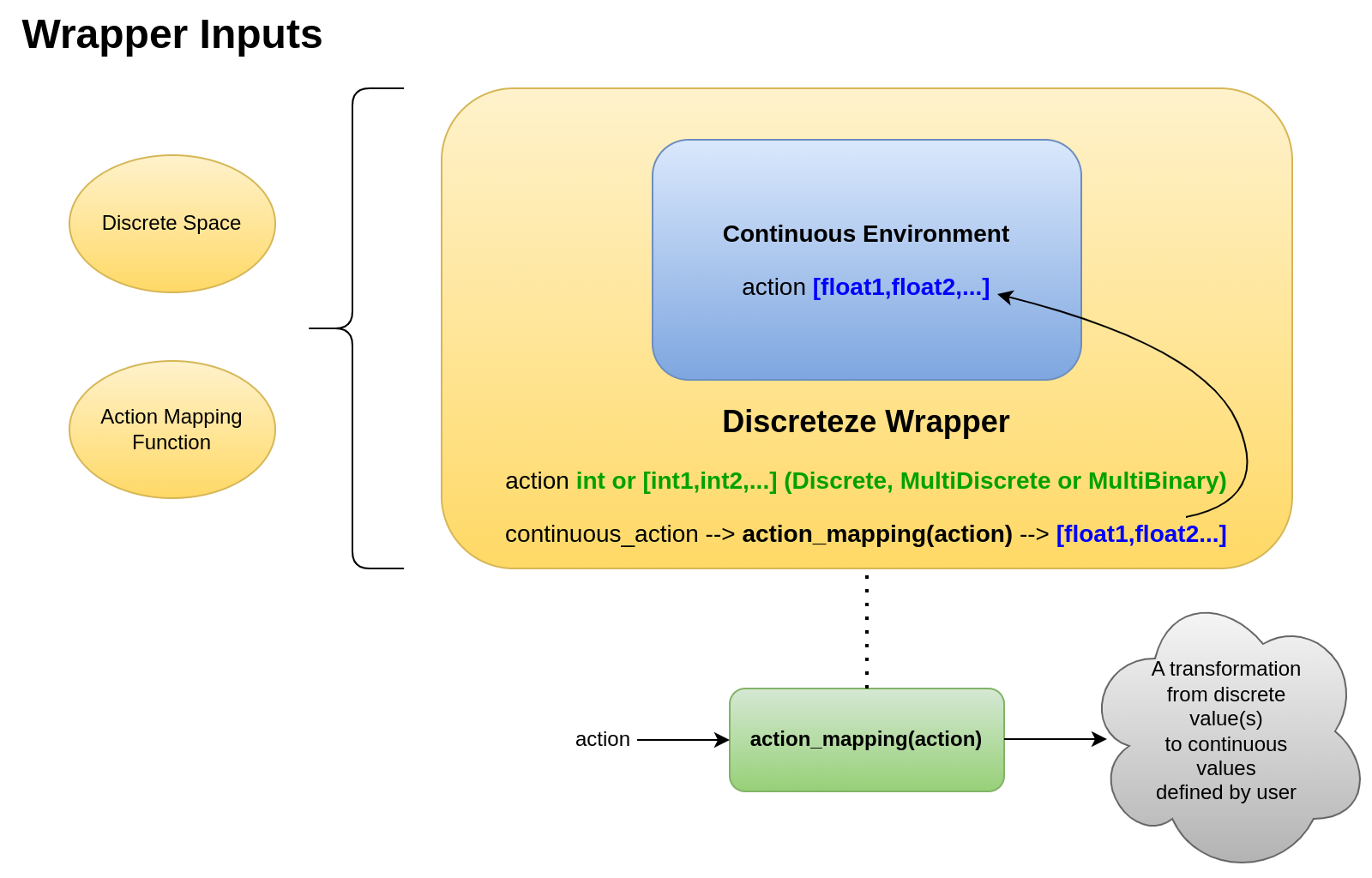
9.5. DiscretizeEnv
Wrapper to discretize the action space. Discrete space must be defined following the Gymnasium standard. This space
should be gym.spaces.Discrete, gym.spaces.MultiDiscrete or gym.spaces.MultiBinary. An action mapping function
is also given, in order to map this/these value(s) into ones that fit the underlying continuous environment (before to send it to the simulator).
Important
The discrete space must discretize the original continuous space. Therefore, discrete space only should reach values which are considered in the original environment action space.
This action mapping function can be defined by users to specify how to jump from discrete to continuous values. If action mapping function output doesn’t match with original environment action space, an error will be raised. See Environment Discretization Wrapper for an example of use.
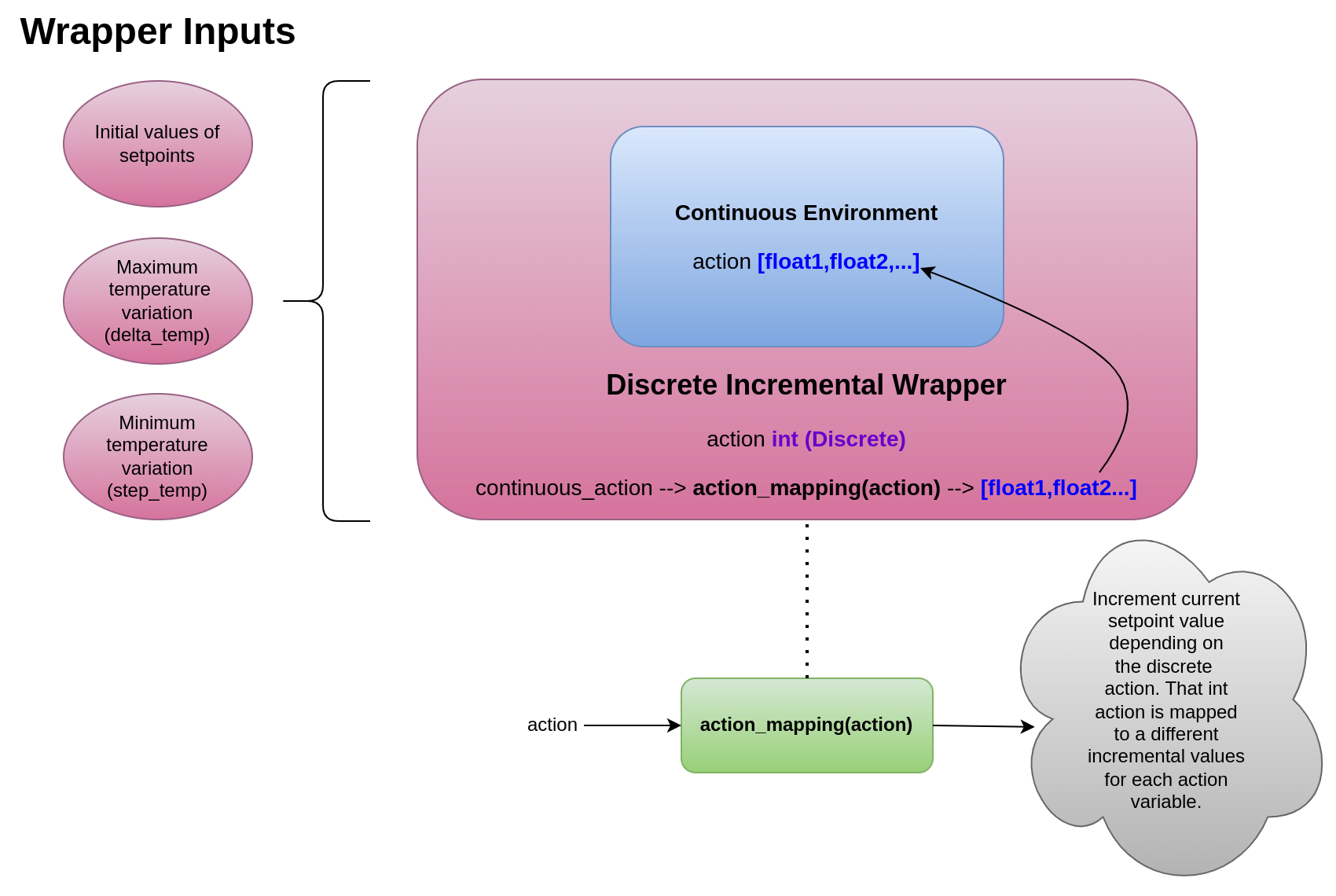
9.6. DiscreteIncrementalWrapper
A wrapper for an incremental setpoint action space environment. This wrapper will update an environment, converting it in a discrete environment with an action mapping function and action space depending on the step and delta specified. The action will be sum with current setpoint values instead of overwrite the latest action. Then, the action is the current setpoint values with the increase instead of the discrete value action whose purpose is to define the increment/decrement itself.
9.7. NormalizeObservation
It is used to transform observation received from simulator in values between -1 and 1. It is based in the dynamic normalization wrapper of Gymnasium. At the beginning, it is not precise and the values may be out of range usually, so use this wrapper carefully.
9.8. LoggerWrapper
Wrapper for logging all interactions between agent and environment. Logger class can be selected in the constructor if other type of logging is required. For more information about Sinergym Logger visit Logger.
9.9. MultiObsWrapper
Stack observation received in a history queue (size can be customized).
Note
For examples about how to use these wrappers, visit Wrappers example.
Important
You have to be careful if you are going to use several nested wrappers. A wrapper works on top of the previous one. The order is flexible since Sinergym v3.0.5.