Wrappers
Sinergym provides several wrappers to add functionalities to the environments that are not included by default.
The implementations of these wrappers are available in sinergym/sinergym/utils/wrappers.py.
Custom wrappers can be created by inheriting from gym.Wrapper or one of its variants, as seen in the
Gymnasium documentation.
Note
For examples on how to use these wrappers, refer to Wrappers example.
Important
Take care of the wrapping order when using multiple nested wrappers, as their inputs and outputs may be altered.
Below are the wrappers that are pre-implemented in Sinergym.
MultiObjectiveReward
When using it, every environment step will return a reward vector (one scalar per reward term) instead of a single scalar value. Refer to #301 for additional information.
PreviousObservationWrapper
This wrapper adds observations from the previous timestep to the current environment observation. You can select the variables you want to track for their previous observation values.
DatetimeWrapper
Important
It is highly recommended to use the ``DatetimeWrapper`` for optimal temporal encoding in deep reinforcement learning algorithms. This wrapper must be applied manually in your environment’s pipeline if you wish to benefit from state-of-the-art temporal features.
This wrapper transforms datetime variables into a more useful representation for deep RL:
- day_of_month is replaced with day_cos and day_sin (cyclic encoding).
- hour is replaced with hour_cos and hour_sin (cyclic encoding).
- month is replaced with month_cos and month_sin (cyclic encoding).
Cyclic encoding using sine and cosine is essential for deep RL because it preserves the circular nature of temporal variables (e.g., hour 23:59 is close to 00:00).
Note
This wrapper must be applied before NormalizeObservation wrapper, since it modifies the observation space.
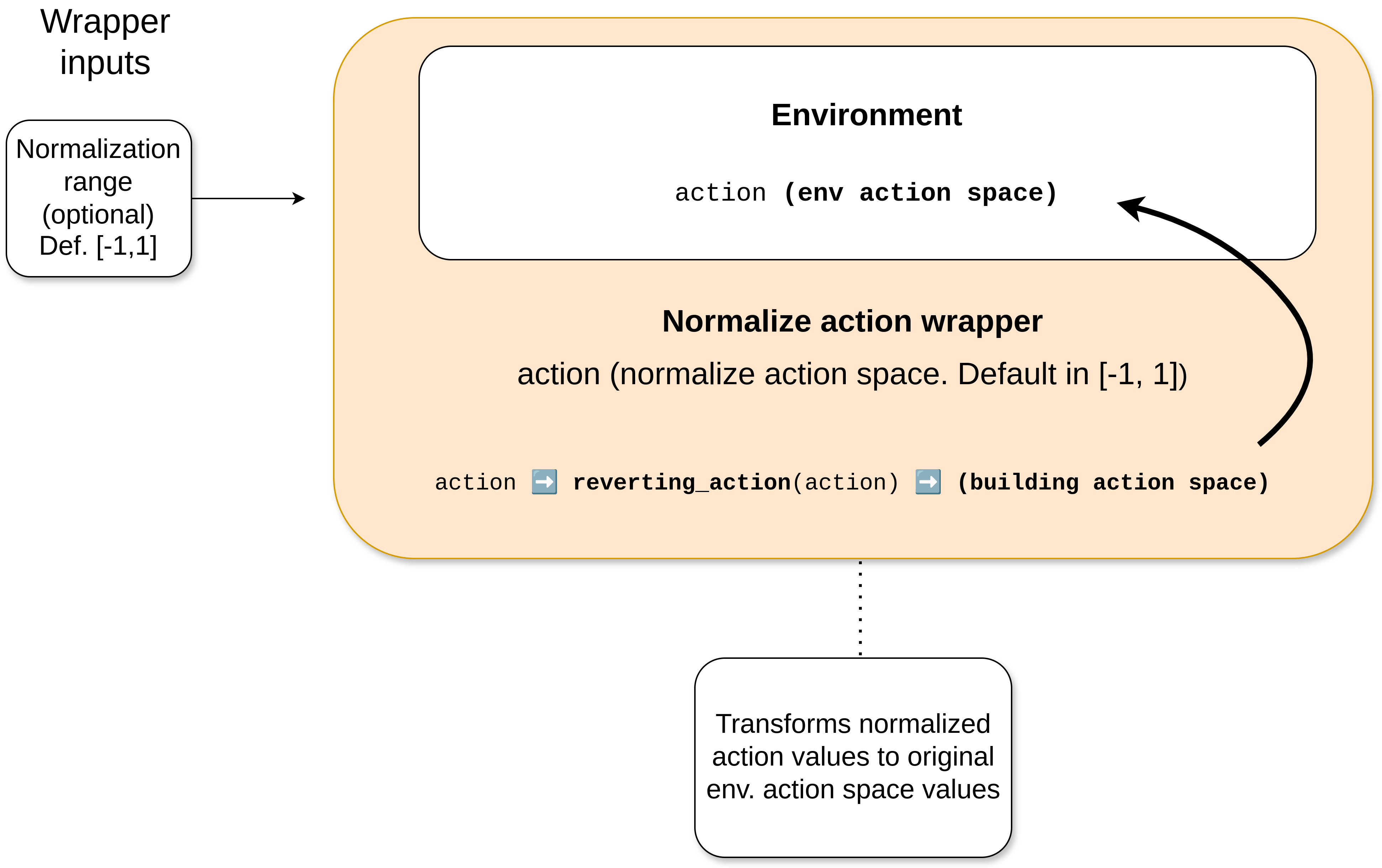
NormalizeAction
This wrapper normalizes the action space. It is particularly useful for DRL algorithms, as normalized action values are generally recommended.
By default, normalization is applied in the range [-1,1]. However, a different range can be specified when the wrapper is instantiated.
Sinergym parses these values to the real action space defined in the original environment internally before sending it to the EnergyPlus Simulator via the API middleware.
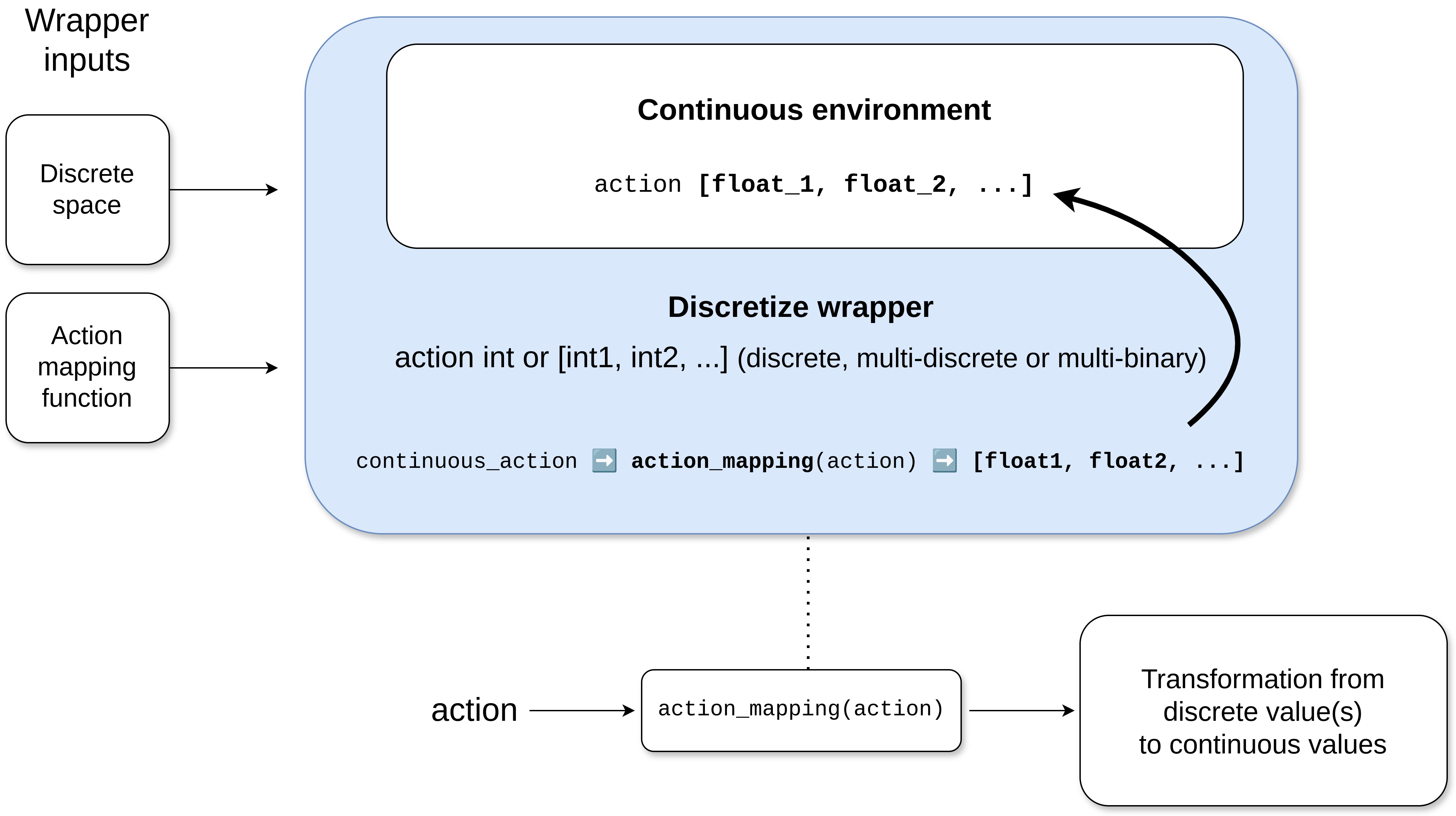
DiscretizeEnv
This wrapper discretizes the action space. The discrete space should be defined according to the Gymnasium standard. This space should be either gym.spaces.Discrete, gym.spaces.MultiDiscrete, or gym.spaces.MultiBinary.
An action mapping function is also provided to map these values into ones that are compatible with the underlying continuous environment, just before sending them to the simulator.
Important
The discrete space must discretize the original continuous space. Hence, the discrete space should only take values that are considered in the original continuous action space.
Users can define this action mapping function to specify the transition from discrete to continuous values. If the output of the action mapping function does not align with the original environment action space, an error will be raised. Refer to Action discretization wrapper for an usage example.
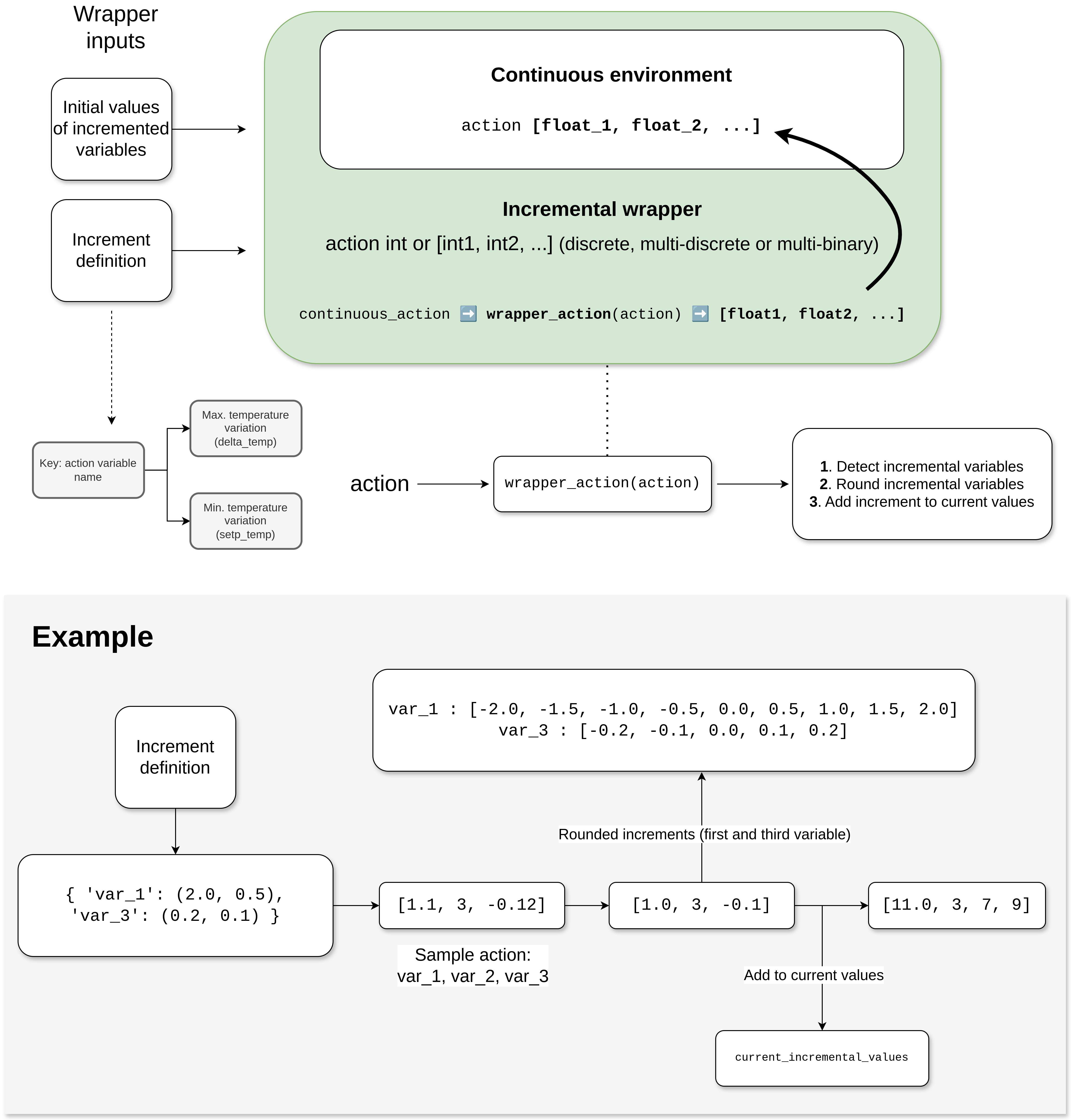
IncrementalWrapper
This wrapper converts some continuous variables into actions that indicate an increment/decrement with respect to their current value, rather than directly setting a value.
A dictionary is given as an argument to calculate the possible increments/decrements for each variable. This dictionary uses the name of each variable to be transformed as the key, while the value is a tuple of values called delta and step, which creates a set of possible increments for each desired variable.
delta: the maximum range of increments and decrements.
step: the interval of intermediate values within the ranges.
The following figure illustrates its operation. Essentially, the values are rounded to the nearest increment value and added to the current real values of the simulation:
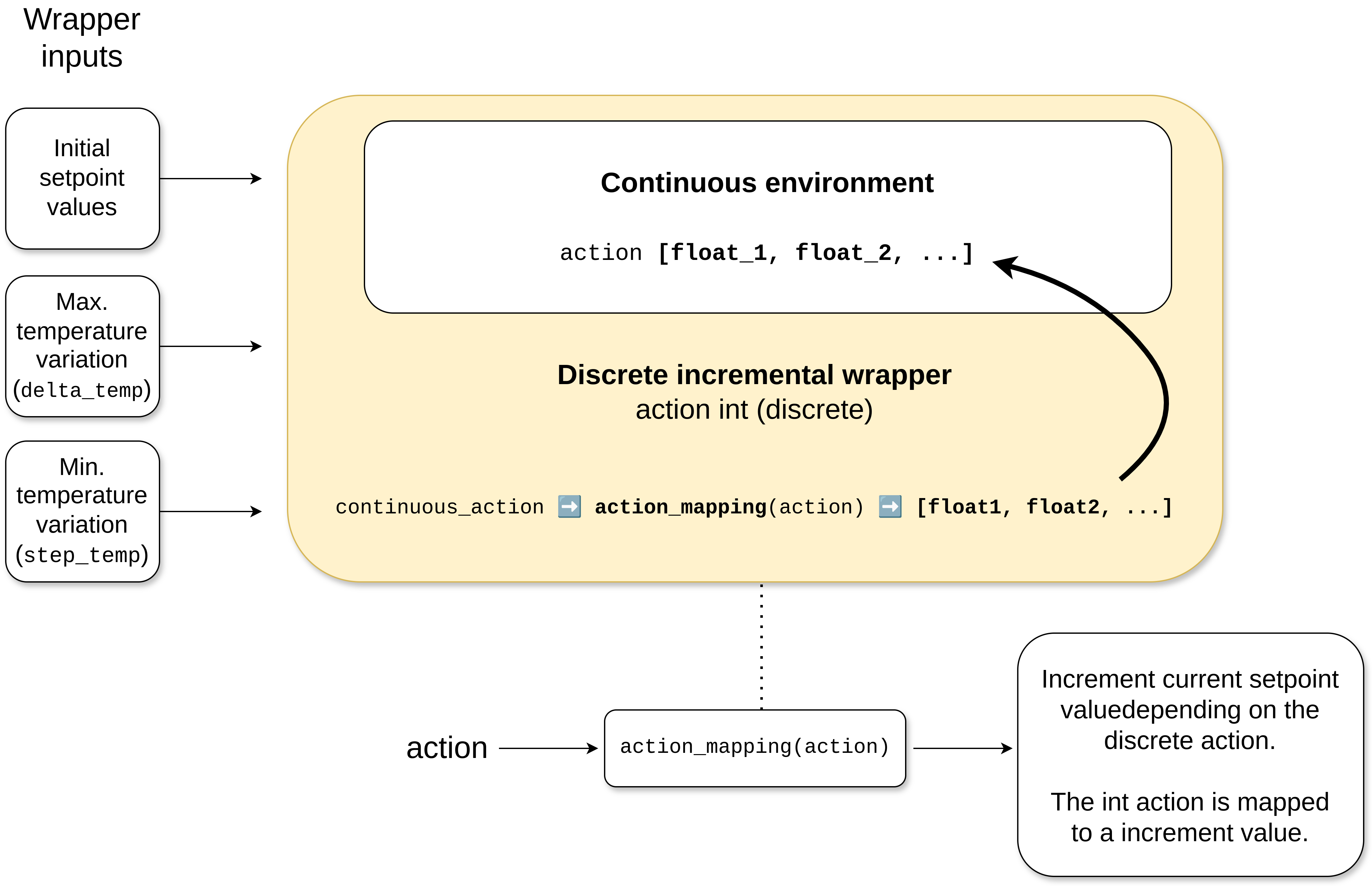
DiscreteIncrementalWrapper
This wrapper updates an environment, transforming it into a discrete environment with an action mapping function and action based on the specified delta and step. The action is added to the current setpoint values rather than overwriting the last action. Therefore, the action is the current setpoint with the increment, rather than the discrete value action which is intended to define the increment/decrement itself.
Warning
This wrapper fully changes the action space from continuous to discrete, meaning that increments/decrements
apply to all variables. In essence, selecting variables individually as the IncrementalWrapper does is not possible.
NormalizeObservation
This wrapper is used to transform observations received from the simulator into values in [-1,1].
It is based on the dynamic normalization wrapper of Gymnasium.
Initially, it may not be precise and the values may often be out of range, so use this wrapper with caution.
However, Sinergym extends its functionality with some additional features:
It includes the last unnormalized observation as an environment attribute, which is useful for logging.
It provides access to the means, standard deviations and count values used for normalization calibration, thus addressing the low-level issues found in the original wrapper.
The mean and variance values are used to normalize the observations following the Welford algorithm.
The count value is used to weigh the updates of the calibrations. The higher the number of interactions, the higher this value becomes, which causes the calibration updates to become progressively smoother. This is important to use if the environment has already been calibrated previously. This value is only used when automatic update is enabled.
Similarly, these calibration values can be set via a method or within the wrapper constructor. These values can be specified either as a list or as
numpyarray in mean and variance and a float in count, or simply writing the file path generated. See API reference for more information.Automatic calibration can be enabled or disabled when interacting with the environment, allowing the calibration to remain static rather than adaptive. This is useful for model evaluation.
In addition, this wrapper saves the count, mean and standard deviation values as part of the Sinergym output. These can be used when loading and a evaluating a trained model.
An example of its use can be found in Loading and evaluating a trained model. It is also important that normalization calibration update is disabled during evaluation.
Sinergym will also save intermediate mean and standard deviation values in files within episode directories, as well as for the best model obtained if LoggerEvalCallback is active during training.
These features are crucial when evaluating models trained using this wrapper. For more details, see #407.
ReduceObservationWrapper
This wrapper reduces the original observation space by subtracting the variables specified in the string list parameter. These removed variables are returned in the info dictionary under the key removed_variables, and are ignored by the agent.
If combined with the LoggerWrapper in subsequent layers, the removed variables will be saved in the output files, even if they are not used. This makes it perfect for monitoring simulation values that are not part of the problem to be solved.
Similarly, any other wrapper applied in layers prior to this one will affect the removed variables, which can be observed in the info dictionary.
When used together with NormalizeObservation, this wrapper also saves a filtered calibration (mean and variance for the kept variables only) in norm_stats/filtered/, both in the episode directory and in the workspace. That allows loading normalization statistics that match the reduced observation space when evaluating an agent without this variables directly.
MultiObsWrapper
This wrapper stacks observations received in a history queue.
The size of the queue can be customized.
WeatherForecastingWrapper
This wrapper adds weather forecast information to the current observation.
EnergyCostWrapper
This wrapper adds energy cost information to the current observation.
Warning
It internally uses the EnergyCostLinearReward reward function, independently of the reward function set when creating the environment.
DeltaTempWrapper
This wrapper adds to the observation space the delta values with respect to the specified zone temperatures, that its, the difference between the zone air temperature and the fixed setpoint value.
It requires that the air temperature and setpoints variables are defined in the wrapper constructor.
If the environment has a unique setpoint variable for all zones, you can specify a single setpoint variable. Otherwise, you can specify a list of variables, one for each zone.
Important
The air temperature variables and setpoints variables should be specified in the same order. The length of these lists should be the same, in case you are not using the same setpoint for all zones.
Logger Wrappers
These wrappers use the Sinergym LoggerStorage class functionalities to save information during environment interactions. For more details, see Logging system overview.
The diagram below illustrates the relationship between the wrappers and the logger, with explanations provided in the following subsections.
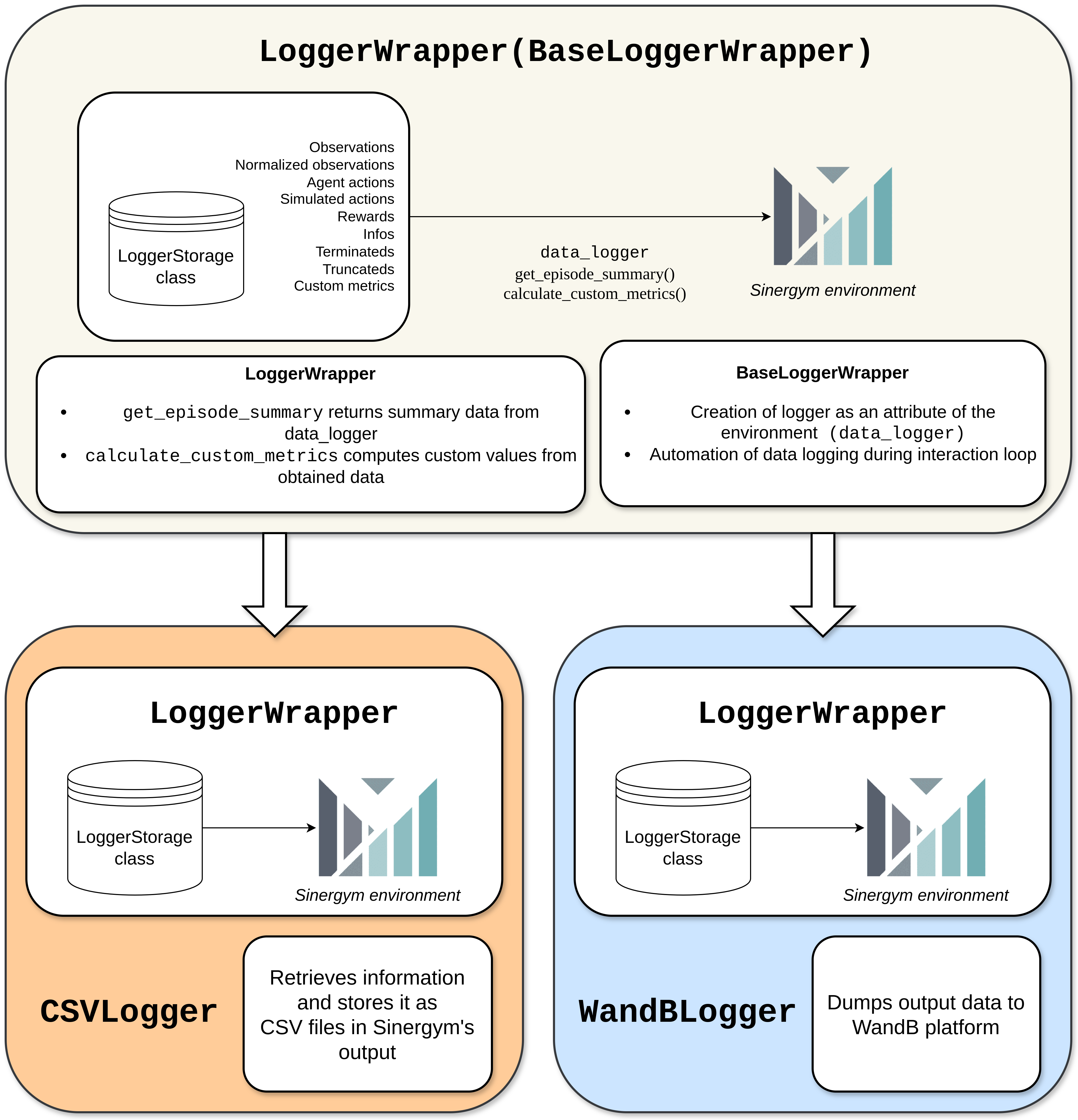
LoggerWrapper
BaseLoggerWrapper is the abstract class for logger wrappers. It stores all the relevant information during environment interactions. A new attribute, data_logger, is included to the environment. This is an instance of LoggerStorage containing the interaction information. A custom LoggerStorage class can be used by passing it to the constructor to change the logging backend.
Inherit from this class to create a new logger wrapper and implement abstract methods to define custom and episode summary metrics from the available data.
Sinergym uses this base class to implement the LoggerWrapper, the default logger, but custom loggers can be implemented easily from this abstract class (see LoggerWrapper customization).
The current summary metrics for this default Sinergym wrapper are: episode_num, mean_reward, std_reward,
mean_reward_comfort_term, std_reward_comfort_term, mean_reward_energy_term, std_reward_energy_term,
mean_abs_comfort_penalty, std_abs_comfort_penalty, mean_abs_energy_penalty, std_abs_energy_penalty,
mean_temperature_violation, std_temperature_violation, mean_power_demand, std_power_demand, cumulative_power_demand, comfort_violation_time(%), length(timesteps), time_elapsed(hours), terminated, truncated
Note how data is refreshed with each new episode. However, this wrapper can be combined with others to store all data and summaries in different locations and formats. For this purpose, Sinergym implements CSVLogger and WandBLogger.
CSVLogger
This wrapper works with the data_logger instance of LoggerWrapper, enabling the parsing and saving of data in CSV files during simulations. A file named progress.csv is generated in the root of the output directory. This file contains general simulation results, updated per episode. The structure of this file is defined in the LoggerWrapper class.
Each episode directory includes a monitor directory with several CSV files for data such as observations, actions, rewards, info and custom metrics, as detailed in Sinergym output.
Please note that the CSVs for observations and info dictionaries are saved with an additional row, as they are saved at the beginning of the episode when reset is called. Subsequently, for a given row with the same index, there would be the observation and info, the action taken in that state, and the reward obtained from that action in that state.
WandBLogger
This wrapper works with the data_logger instance of LoggerWrapper to dump information to the Weights and Biases platform in real-time.
This solution is ideal for monitoring the real-time training process and can be integrated with Stable Baselines 3 callbacks. The initialization process allows the user to define a number of key parameters, including the project, entity, run groups, tags, and whether code or outputs are saved as platform artifacts. Additionally, the user can specify the dump frequency, any excluded info keys, and excluded summary metric keys.
This wrapper can be used with an existing WandB session, eliminating the need to specify the entity or project (which, if provided, will be ignored). In the absence of a pre-existing WandB session, it is necessary to provide the entity and project fields.
This wrapper will only save data on episode summaries once they have reached a minimum of 90% completion. This can be modified when creating the wrapper.
Important
A Weights and Biases account is required to use this wrapper, with an environment variable containing the API key for login.
Context Wrappers
Sinergym provides wrappers to manage context variables dynamically and automatically during simulation (see Context), instead of having to call the context update method of Sinergym environments constantly. This facilitates a convenient management of control profiles for this context that we want to provide in experiments while the control agents improve with respect to these changes.
ScheduledContextWrapper
This wrapper applies predefined context changes at specific dates and times during the simulation.
The wrapper uses a configuration dictionary that maps datetime strings (in format 'MM-DD HH') to lists of context values. When the simulation reaches a matching datetime, the corresponding context values are applied to the context variables.
Parameters:
scheduled_context (Dict[str, List[float]]): Dictionary mapping datetime strings to context values. Keys must be in format
'MM-DD HH'(e.g.,'01-15 14'for January 15th at 2 PM). Values must be lists of floats with length equal to the number of context variables. The values are applied in order to the context variables.
Unlike the other context wrappers, this wrapper uses a fixed configuration that remains the same across all episodes, making it suitable for scenarios where you want to test specific context change schedules.
Example:
from sinergym.utils.wrappers import ScheduledContextWrapper
env = make('Eplus-5zone-hot-continuous-v1')
# Define context changes at specific dates and times
scheduled_context = {
'01-15 10': [0.8], # January 15th at 10 AM
'01-20 14': [0.5], # January 20th at 2 PM
'02-10 09': [0.9], # February 10th at 9 AM
}
env = ScheduledContextWrapper(
env=env,
scheduled_context=scheduled_context
)
ProbabilisticContextWrapper
This wrapper automatically updates context variables probabilistically at each simulation step. It provides flexible control over when and how context changes occur, making it ideal for simulating stochastic disturbances such as varying occupancy patterns, equipment failures, or weather-related uncertainties.
Update Modes:
The wrapper supports two probability modes:
Float mode (
update_probabilityas float): At each step, there’s a probability that triggers a context update event. When triggered, all context variables are updated at the same time. Defaults to 0.1 (10% per step).List mode (
update_probabilityas list): Each context variable is independently evaluated at each step according to its own probability. This allows different variables to update at different times.
Update Types:
Absolute updates: New random values are sampled from the context space bounds.
Delta updates (
delta_update=True): Incremental changes are applied to current values, simulating gradual transitions. Values are automatically clipped to stay within bounds.
Value Synchronization:
Independent values (
global_value=False): Each context variable gets its own random value.Synchronized values (
global_value=True): All context variables receive the same value, useful for correlated changes. In this case, the context space should have the same range for all variables.
Parameters:
context_space (gym.spaces.Box): Defines the valid value range for each context variable. The shape must match the number of context variables. Each dimension defines the valid range for the corresponding variable.
update_probability (Union[float, List[float]]): Probability of context updates. If float (0.0 to 1.0), all variables update together when triggered. If list, each variable is evaluated independently. Length must match the number of context variables. Defaults to 0.1.
global_value (bool): If
True, all variables receive the same random value. IfFalse, each variable gets an independent value. Defaults toFalse.delta_update (bool): If
True, applies incremental changes to current values instead of absolute values. Defaults toFalse.delta_value (float, optional): Maximum absolute change when
delta_update=True. The actual delta is randomly sampled from [-delta_value, delta_value]. Required whendelta_update=True.
Example:
from sinergym.utils.wrappers import ProbabilisticContextWrapper
import gymnasium as gym
import numpy as np
env = make('Eplus-5zone-hot-continuous-v1')
# Define context space for 1 context variable (e.g., occupancy)
context_space = gym.spaces.Box(
low=np.array([0.3], dtype=np.float32),
high=np.array([0.9], dtype=np.float32),
shape=(1,),
dtype=np.float32,
)
# Update context with 5% probability per step using incremental changes
env = ProbabilisticContextWrapper(
env=env,
context_space=context_space,
update_probability=0.05,
delta_update=True,
delta_value=0.1
)