DRL usage example
In this notebook example, we will use Stable Baselines 3 to train and load a deep reinforcement learning agent.
Note how Sinergym is entirely agnostic to any DRL algorithm (though it features custom callbacks and a close integration with SB3), so it can be used with any DRL library compatible with Gymnasium interface.
Note: For more up-to-date examples, see the Deep Reinforcement Learning section in the Sinergym documentation. It references some available scripts in Sinergym and explains how they work.
Training a model
We will use the train_agent.py script provided with Sinergym. This script leverages all the capabilities of Sinergym to work with deep reinforcement learning algorithms, easily configuring the environment and agent parameters by using a JSON configuration file.
For more details on how to run train_agent.py, please refer to Train a model.
[ ]:
import sys
from datetime import datetime
import gymnasium as gym
import numpy as np
import wandb
from stable_baselines3.common.callbacks import CallbackList
from stable_baselines3.common.logger import HumanOutputFormat
from stable_baselines3.common.logger import Logger as SB3Logger
import sinergym
from sinergym.utils.callbacks import *
from sinergym.utils.constants import *
from sinergym.utils.logger import WandBOutputFormat
from sinergym.utils.rewards import *
from sinergym.utils.wrappers import *
First, let’s define some configurations…
[ ]:
# Environment ID
environment = 'Eplus-5zone-mixed-continuous-stochastic-v1'
# Training episodes
episodes = 5
# Name of the experiment
experiment_date = datetime.today().strftime('%Y-%m-%d_%H:%M')
experiment_name = 'SB3_PPO-' + environment + \
'-episodes-' + str(episodes)
experiment_name += '_' + experiment_date
Now, we are ready to create the Gymnasium environment.
We will use the previously defined environment name. Just remember that you can change the default environment configuration. We will also create an evaluation environment (eval_env).
If desired, we can replace the environment name with the experiment name.
[8]:
env = gym.make(environment, env_name=experiment_name)
eval_env = gym.make(environment, env_name=experiment_name+'_EVALUATION')
#==============================================================================================#
[ENVIRONMENT] (INFO) : Creating Gymnasium environment.
[ENVIRONMENT] (INFO) : Name: SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57
#==============================================================================================#
[MODELING] (INFO) : Experiment working directory created.
[MODELING] (INFO) : Working directory: /workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57-res1
[MODELING] (INFO) : Model Config is correct.
[MODELING] (INFO) : Update building model Output:Variable with variable names.
[MODELING] (INFO) : Update building model Output:Meter with meter names.
[MODELING] (INFO) : Runperiod established.
[MODELING] (INFO) : Episode length (seconds): 31536000.0
[MODELING] (INFO) : timestep size (seconds): 900.0
[MODELING] (INFO) : timesteps per episode: 35040
[REWARD] (INFO) : Reward function initialized.
[ENVIRONMENT] (INFO) : Environment created successfully.
#==============================================================================================#
[ENVIRONMENT] (INFO) : Creating Gymnasium environment.
[ENVIRONMENT] (INFO) : Name: SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57_EVALUATION
#==============================================================================================#
[MODELING] (INFO) : Experiment working directory created.
[MODELING] (INFO) : Working directory: /workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57_EVALUATION-res1
[MODELING] (INFO) : Model Config is correct.
[MODELING] (INFO) : Update building model Output:Variable with variable names.
[MODELING] (INFO) : Update building model Output:Meter with meter names.
[MODELING] (INFO) : Runperiod established.
[MODELING] (INFO) : Episode length (seconds): 31536000.0
[MODELING] (INFO) : timestep size (seconds): 900.0
[MODELING] (INFO) : timesteps per episode: 35040
[REWARD] (INFO) : Reward function initialized.
[ENVIRONMENT] (INFO) : Environment created successfully.
We can also add some wrappers to the environment. We will use an action and observation normalization wrapper and the Sinergym logger.
Normalization is highly recommended for DRL algorithms, while the logger is used to monitor and log environment interactions and save the data, and then dump it into CSV files and/or Weights and Biases.
[ ]:
env = NormalizeObservation(env)
env = NormalizeAction(env)
env = LoggerWrapper(env)
env = CSVLogger(env)
# Discomment the following line to log to WandB (remember to set the API key as an environment variable)
# env = WandBLogger(env,
# entity='test-project',
# project_name='sail_ugr',
# run_name=experiment_name,
# group='Train_example',
# tags=['DRL', 'PPO', '5zone', 'continuous', 'stochastic', 'v1'],
# save_code = True,
# dump_frequency = 1000,
# artifact_save = False)
eval_env = NormalizeObservation(eval_env)
eval_env = NormalizeAction(eval_env)
eval_env = LoggerWrapper(eval_env)
eval_env = CSVLogger(eval_env)
# Evaluation env is not required to be wrapped with WandBLogger, since the calculations are added in the same WandB session than the training env by using the sinergym LoggerEvalCallback
[WRAPPER NormalizeObservation] (INFO) : Wrapper initialized.
[WRAPPER NormalizeAction] (INFO) : New normalized action Space: Box(-1.0, 1.0, (2,), float32)
[WRAPPER NormalizeAction] (INFO) : Wrapper initialized
[WRAPPER LoggerWrapper] (INFO) : Wrapper initialized.
[WRAPPER CSVLogger] (INFO) : Wrapper initialized.
[WRAPPER NormalizeObservation] (INFO) : Wrapper initialized.
[WRAPPER NormalizeAction] (INFO) : New normalized action Space: Box(-1.0, 1.0, (2,), float32)
[WRAPPER NormalizeAction] (INFO) : Wrapper initialized
[WRAPPER LoggerWrapper] (INFO) : Wrapper initialized.
[WRAPPER CSVLogger] (INFO) : Wrapper initialized.
At this point, the environment is set up and ready to use. We will create a sample PPO model.
[10]:
# In this case, all the hyperparameters are the default ones
model = PPO('MlpPolicy', env, verbose=1)
Using cpu device
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
If WandBLogger is active, we can log all the hyperparameters as follows:
[11]:
# Register hyperparameters in wandb if it is wrapped
if is_wrapped(env, WandBLogger):
experiment_params = {
'sinergym-version': sinergym.__version__,
'python-version': sys.version
}
# experiment_params.update(conf)
env.get_wrapper_attr('wandb_run').config.update(experiment_params)
Evaluations will be run periodically during a number of episodes to determine if the current version of the model improves the best one obtained until that training episode.
The generated output will be stored depending on the logger wrapper configuration. We will use the LoggerEval callback to print and save the current best model during training, saving data in both local CSV files and WandB.
[ ]:
callbacks = []
# Set up Evaluation logging and saving best model
eval_callback = LoggerEvalCallback(
eval_env=eval_env,
train_env=env,
n_eval_episodes=1,
eval_freq_episodes=2,
deterministic=True)
callbacks.append(eval_callback)
callback = CallbackList(callbacks)
To add the SB3 logging values in the same WandB session, we need to create a compatible WandB output format (which calls the WandB log method during training).
Sinergym provides WandBOutputFormat for this purpose:
[ ]:
# wandb logger and setting in SB3
if is_wrapped(env, WandBLogger):
logger = SB3Logger(
folder=None,
output_formats=[
HumanOutputFormat(
sys.stdout,
max_length=120),
WandBOutputFormat()])
model.set_logger(logger)
This is the total number of time steps for training:
[14]:
timesteps = episodes * (env.get_wrapper_attr('timestep_per_episode') - 1)
Now, it is time to train the model with the previously defined callback. This may take a few minutes, depending on your computer.
[15]:
model.learn(
total_timesteps=timesteps,
callback=callback,
log_interval=100)
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode.
[ENVIRONMENT] (INFO) : Episode 1: SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created.
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model.
[MODELING] (INFO) : Weather noise applied in columns: ['drybulb']
[ENVIRONMENT] (INFO) : Saving episode output path.
[ENVIRONMENT] (INFO) : Episode 1 started.
[SIMULATOR] (INFO) : handlers initialized.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
Simulation Progress [Episode 1]: 100%|██████████| 100/100 [00:38<00:00, 2.59%/s, 100% completed]
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode.
[ENVIRONMENT] (INFO) : Episode 2: SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created.
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model.
[MODELING] (INFO) : Weather noise applied in columns: ['drybulb']
[ENVIRONMENT] (INFO) : Saving episode output path.
[ENVIRONMENT] (INFO) : Episode 2 started.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
[WRAPPER CSVLogger] (INFO) : Environment closed, data updated in monitor and progress.csv.
Simulation Progress [Episode 2]: 100%|██████████| 100/100 [00:35<00:00, 2.83%/s, 100% completed]
[ENVIRONMENT] (INFO) : Environment closed. [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode.
[ENVIRONMENT] (INFO) : Episode 1: SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57_EVALUATION
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created.
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model.
[MODELING] (INFO) : Weather noise applied in columns: ['drybulb']
[ENVIRONMENT] (INFO) : Saving episode output path.
[ENVIRONMENT] (INFO) : Episode 1 started.
[SIMULATOR] (INFO) : handlers initialized.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
[EVALUATION] (INFO) : Eval num_timesteps=70078, episode_reward=-0.28 + /- 0.35
[EVALUATION] (INFO) : New best mean reward!
Simulation Progress [Episode 1]: 100%|██████████| 100/100 [00:14<00:00, 8.43%/s, 100% completed]
/workspaces/sinergym/sinergym/utils/callbacks.py:130: FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
self.evaluation_metrics = self.evaluation_metrics._append(
[WRAPPER CSVLogger] (INFO) : Environment closed, data updated in monitor and progress.csv.
Simulation Progress [Episode 1]: 100%|██████████| 100/100 [00:21<00:00, 4.75%/s, 100% completed]
[ENVIRONMENT] (INFO) : Environment closed. [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57_EVALUATION]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode.
[ENVIRONMENT] (INFO) : Episode 3: SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created.
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model.
[MODELING] (INFO) : Weather noise applied in columns: ['drybulb']
[ENVIRONMENT] (INFO) : Saving episode output path.
[ENVIRONMENT] (INFO) : Episode 3 started.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
Simulation Progress [Episode 3]: 100%|██████████| 100/100 [00:37<00:00, 2.70%/s, 100% completed]
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode.
[ENVIRONMENT] (INFO) : Episode 4: SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created.
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model.
[MODELING] (INFO) : Weather noise applied in columns: ['drybulb']
[ENVIRONMENT] (INFO) : Saving episode output path.
[ENVIRONMENT] (INFO) : Episode 4 started.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
[WRAPPER CSVLogger] (INFO) : Environment closed, data updated in monitor and progress.csv.
Simulation Progress [Episode 4]: 100%|██████████| 100/100 [00:35<00:00, 2.83%/s, 100% completed]
[ENVIRONMENT] (INFO) : Environment closed. [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode.
[ENVIRONMENT] (INFO) : Episode 2: SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57_EVALUATION
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created.
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model.
[MODELING] (INFO) : Weather noise applied in columns: ['drybulb']
[ENVIRONMENT] (INFO) : Saving episode output path.
[ENVIRONMENT] (INFO) : Episode 2 started.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
[EVALUATION] (INFO) : Eval num_timesteps=140156, episode_reward=-0.23 + /- 0.27
[EVALUATION] (INFO) : New best mean reward!
[WRAPPER CSVLogger] (INFO) : Environment closed, data updated in monitor and progress.csv.
Simulation Progress [Episode 2]: 100%|██████████| 100/100 [00:20<00:00, 4.79%/s, 100% completed]
[ENVIRONMENT] (INFO) : Environment closed. [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57_EVALUATION]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode.
[ENVIRONMENT] (INFO) : Episode 5: SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created.
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model.
[MODELING] (INFO) : Weather noise applied in columns: ['drybulb']
[ENVIRONMENT] (INFO) : Saving episode output path.
[ENVIRONMENT] (INFO) : Episode 5 started.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
Simulation Progress [Episode 5]: 100%|██████████| 100/100 [00:36<00:00, 2.72%/s, 100% completed]
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode.
[ENVIRONMENT] (INFO) : Episode 6: SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created.
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model.
[MODELING] (INFO) : Weather noise applied in columns: ['drybulb']
[ENVIRONMENT] (INFO) : Saving episode output path.
[ENVIRONMENT] (INFO) : Episode 6 started.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
Simulation Progress [Episode 6]: 4%|▍ | 4/100 [00:00<00:10, 9.14%/s, 4% completed]
[15]:
<stable_baselines3.ppo.ppo.PPO at 0x7f7ec7eb7740>
Once the training process has finished, the last version of the model is saved. The count, mean and var values used for normalization are also stored in the in Sinergym training output folder, in order to use them for model evaluation.
Visit the NormalizeObservation documentation for additional information.
[16]:
model.save(env.get_wrapper_attr('workspace_path') + '/model')
Again, remember to close the environment.
If WandB is active, this will save both artifacts and output data remotely.
[17]:
env.close()
[WRAPPER CSVLogger] (INFO) : Environment closed, data updated in monitor and progress.csv.
Simulation Progress [Episode 6]: 4%|▍ | 4/100 [00:01<00:28, 3.39%/s, 4% completed]
[ENVIRONMENT] (INFO) : Environment closed. [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_07:57]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data.
Although results are stored locally, you can also follow the execution of any experiments in WandB:
Once in WandB, you will see the corresponding projects created:
The training hyperparameters:

Registered artifacts (if evaluation is enabled, the best model obtained is also registered):

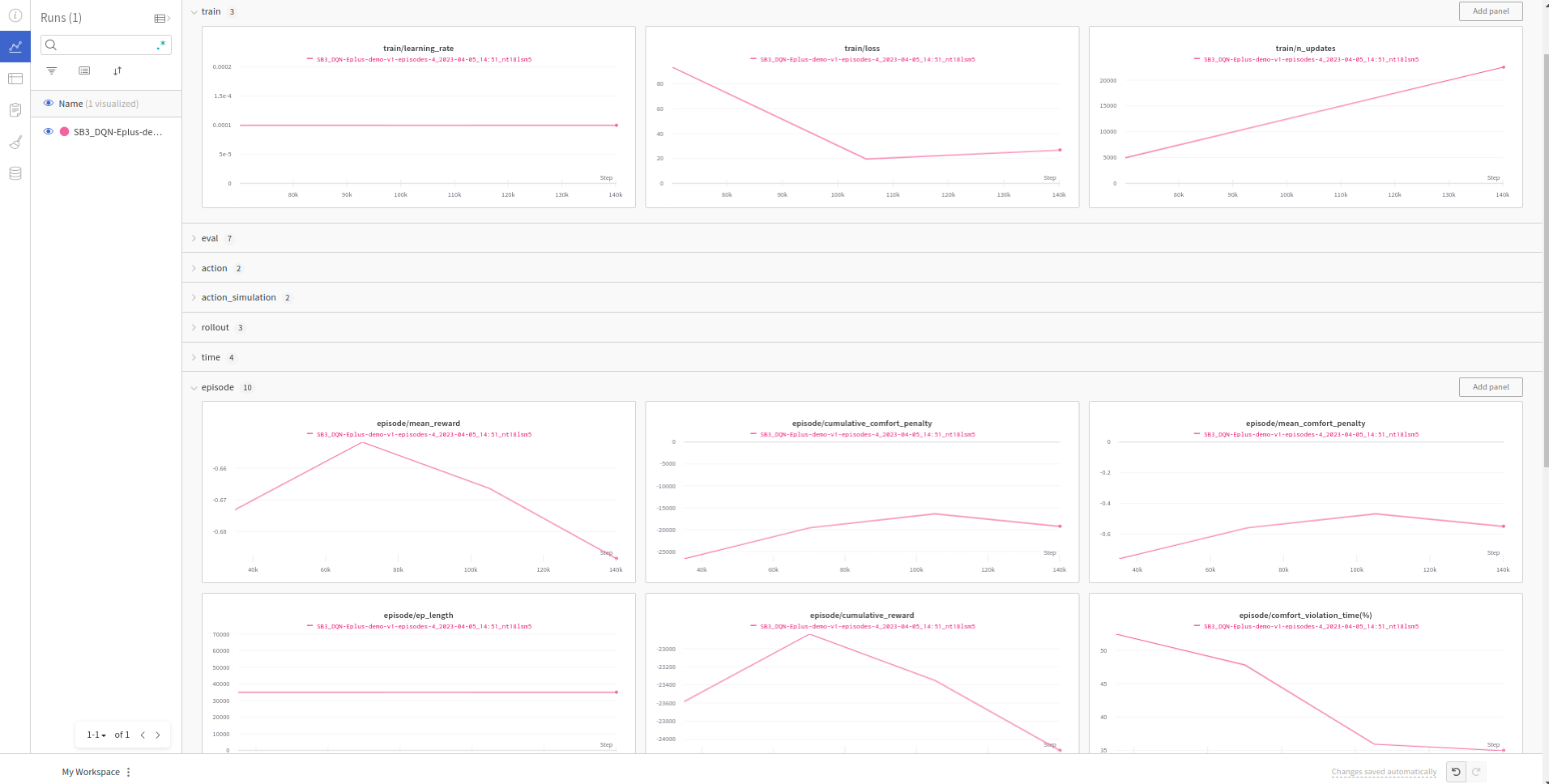
Real-time visualization of metrics:
Loading and evaluating a trained model
We will use the load_agent.py script for loading a trained model. For more details on how to run load_agent.py, please refer to Load a trained model.
First, we define the Sinergym environment to be used for testing the loaded agent, and the name of the evaluation experiment:
[ ]:
# Environment ID
environment = 'Eplus-5zone-mixed-continuous-stochastic-v1'
# Episodes
episodes = 5
# Evaluation name
evaluation_date = datetime.today().strftime('%Y-%m-%d_%H:%M')
evaluation_name = 'SB3_PPO-EVAL-' + environment + \
'-episodes-' + str(episodes)
evaluation_name += '_' + evaluation_date
We will now create the Gymnasium environment. We can use the evaluation experiment name to rename the environment.
It is essential to wrap the environment with the same wrappers used for training if the action or observation spaces were modified.
If you are loading a pre-trained model and using the observation space normalization wrapper, you should use count, means and standard deviations calibrated during the training process for a fair evaluation. count, mean and var values are saved in the Sinergym training output directory as a .txt file automatically. You can use a list or numpy array format (float in count), or just set the .txt path directly in the constructor.
It is also important to deactivate calibration update during evaluations. This is done automatically by the LoggerEvalCallback.
[ ]:
evaluation_env = gym.make(environment, env_name=evaluation_name)
evaluation_env = NormalizeObservation(evaluation_env, mean=env.get_wrapper_attr(
"mean"), var=env.get_wrapper_attr("var"), count=env.get_wrapper_attr("count"), automatic_update=False)
evaluation_env = NormalizeAction(evaluation_env)
evaluation_env = LoggerWrapper(evaluation_env)
evaluation_env = CSVLogger(evaluation_env)
# If you want to log the evaluation interactions to WandB, use WandBLogger too
#==============================================================================================#
[ENVIRONMENT] (INFO) : Creating Gymnasium environment.
[ENVIRONMENT] (INFO) : Name: SB3_PPO-EVAL-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_08:01
#==============================================================================================#
[MODELING] (INFO) : Experiment working directory created.
[MODELING] (INFO) : Working directory: /workspaces/sinergym/examples/Eplus-env-SB3_PPO-EVAL-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-09-10_08:01-res1
[MODELING] (INFO) : Model Config is correct.
[MODELING] (INFO) : Update building model Output:Variable with variable names.
[MODELING] (INFO) : Update building model Output:Meter with meter names.
[MODELING] (INFO) : Runperiod established.
[MODELING] (INFO) : Episode length (seconds): 31536000.0
[MODELING] (INFO) : timestep size (seconds): 900.0
[MODELING] (INFO) : timesteps per episode: 35040
[REWARD] (INFO) : Reward function initialized.
[ENVIRONMENT] (INFO) : Environment created successfully.
[WRAPPER NormalizeObservation] (INFO) : Wrapper initialized.
[WRAPPER NormalizeAction] (INFO) : New normalized action Space: Box(-1.0, 1.0, (2,), float32)
[WRAPPER NormalizeAction] (INFO) : Wrapper initialized
[WRAPPER LoggerWrapper] (INFO) : Wrapper initialized.
[WRAPPER CSVLogger] (INFO) : Wrapper initialized.
We will load the Stable Baselines 3 PPO model from local, but we could also use a remote model stored in WandB.
[ ]:
# get wandb artifact path for loading the model
if is_wrapped(evaluation_env, WandBLogger):
wandb_run = evaluation_env.get_wrapper_attr('wandb_run')
else:
wandb_run = wandb.init(entity='sail_ugr')
load_artifact_entity = 'sail_ugr'
load_artifact_project = 'sinergym'
load_artifact_name = experiment_name
load_artifact_tag = 'latest'
load_artifact_model_path = 'Sinergym_output/evaluation/best_model.zip'
wandb_path = load_artifact_entity + '/' + load_artifact_project + \
'/' + load_artifact_name + ':' + load_artifact_tag
# Download artifact
artifact = wandb_run.use_artifact(wandb_path)
artifact.get_path(load_artifact_model_path).download('.')
# Set model path to local wandb file downloaded
model_path = './' + load_artifact_model_path
model = PPO.load(model_path)
wandb: Currently logged in as: alex_ugr (sail_ugr). Use `wandb login --relogin` to force relogin
/workspaces/sinergym/examples/wandb/run-20240910_080136-00hy8l6g
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
File /usr/local/lib/python3.12/dist-packages/wandb/apis/normalize.py:41, in normalize_exceptions.<locals>.wrapper(*args, **kwargs)
40 try:
---> 41 return func(*args, **kwargs)
42 except requests.HTTPError as error:
File /usr/local/lib/python3.12/dist-packages/wandb/apis/public/api.py:1034, in Api.artifact(self, name, type)
1033 entity, project, artifact_name = self._parse_artifact_path(name)
-> 1034 artifact = wandb.Artifact._from_name(
1035 entity, project, artifact_name, self.client
1036 )
1037 if type is not None and artifact.type != type:
File /usr/local/lib/python3.12/dist-packages/wandb/sdk/artifacts/artifact.py:258, in Artifact._from_name(cls, entity, project, name, client)
242 query = gql(
243 """
244 query ArtifactByName(
(...)
256 + cls._get_gql_artifact_fragment()
257 )
--> 258 response = client.execute(
259 query,
260 variable_values={
261 "entityName": entity,
262 "projectName": project,
263 "name": name,
264 },
265 )
266 project_attrs = response.get("project")
File /usr/local/lib/python3.12/dist-packages/wandb/sdk/lib/retry.py:212, in retriable.<locals>.decorator.<locals>.wrapped_fn(*args, **kargs)
210 @functools.wraps(fn)
211 def wrapped_fn(*args: Any, **kargs: Any) -> Any:
--> 212 return retrier(*args, **kargs)
File /usr/local/lib/python3.12/dist-packages/wandb/sdk/lib/retry.py:131, in Retry.__call__(self, *args, **kwargs)
130 try:
--> 131 result = self._call_fn(*args, **kwargs)
132 # Only print resolved attempts once every minute
File /usr/local/lib/python3.12/dist-packages/wandb/apis/public/api.py:70, in RetryingClient.execute(self, *args, **kwargs)
69 try:
---> 70 return self._client.execute(*args, **kwargs)
71 except requests.exceptions.ReadTimeout:
File /usr/local/lib/python3.12/dist-packages/wandb/vendor/gql-0.2.0/wandb_gql/client.py:52, in Client.execute(self, document, *args, **kwargs)
50 self.validate(document)
---> 52 result = self._get_result(document, *args, **kwargs)
53 if result.errors:
File /usr/local/lib/python3.12/dist-packages/wandb/vendor/gql-0.2.0/wandb_gql/client.py:60, in Client._get_result(self, document, *args, **kwargs)
59 if not self.retries:
---> 60 return self.transport.execute(document, *args, **kwargs)
62 last_exception = None
File /usr/local/lib/python3.12/dist-packages/wandb/sdk/lib/gql_request.py:59, in GraphQLSession.execute(self, document, variable_values, timeout)
58 request = self.session.post(self.url, **post_args)
---> 59 request.raise_for_status()
61 result = request.json()
File /usr/local/lib/python3.12/dist-packages/requests/models.py:1024, in Response.raise_for_status(self)
1023 if http_error_msg:
-> 1024 raise HTTPError(http_error_msg, response=self)
HTTPError: 400 Client Error: Bad Request for url: https://api.wandb.ai/graphql
During handling of the above exception, another exception occurred:
CommError Traceback (most recent call last)
Cell In[20], line 15
12 wandb_path = load_artifact_entity + '/' + load_artifact_project + \
13 '/' + load_artifact_name + ':' + load_artifact_tag
14 # Download artifact
---> 15 artifact = wandb_run.use_artifact(wandb_path)
16 artifact.get_path(load_artifact_model_path).download('.')
17 # Set model path to local wandb file downloaded
File /usr/local/lib/python3.12/dist-packages/wandb/sdk/wandb_run.py:401, in _run_decorator._noop_on_finish.<locals>.decorator_fn.<locals>.wrapper_fn(self, *args, **kwargs)
398 @functools.wraps(func)
399 def wrapper_fn(self: Type["Run"], *args: Any, **kwargs: Any) -> Any:
400 if not getattr(self, "_is_finished", False):
--> 401 return func(self, *args, **kwargs)
403 default_message = (
404 f"Run ({self.id}) is finished. The call to `{func.__name__}` will be ignored. "
405 f"Please make sure that you are using an active run."
406 )
407 resolved_message = message or default_message
File /usr/local/lib/python3.12/dist-packages/wandb/sdk/wandb_run.py:391, in _run_decorator._attach.<locals>.wrapper(self, *args, **kwargs)
389 raise e
390 cls._is_attaching = ""
--> 391 return func(self, *args, **kwargs)
File /usr/local/lib/python3.12/dist-packages/wandb/sdk/wandb_run.py:3024, in Run.use_artifact(self, artifact_or_name, type, aliases, use_as)
3022 name = artifact_or_name
3023 public_api = self._public_api()
-> 3024 artifact = public_api.artifact(type=type, name=name)
3025 if type is not None and type != artifact.type:
3026 raise ValueError(
3027 "Supplied type {} does not match type {} of artifact {}".format(
3028 type, artifact.type, artifact.name
3029 )
3030 )
File /usr/local/lib/python3.12/dist-packages/wandb/apis/normalize.py:51, in normalize_exceptions.<locals>.wrapper(*args, **kwargs)
49 else:
50 message = error.response
---> 51 raise CommError(message, error)
52 except RetryError as err:
53 if (
54 "response" in dir(err.last_exception)
55 and err.last_exception.response is not None
56 ):
CommError: invalid alias. aliases must be specified as collectionName:alias (Error 400: Bad Request)
It should be noted that the model can be loaded from an artifact belonging to a different entity or project, provided that it is accessible. This is independent of the entity or project that is being used to register the evaluation of the loaded model.
The next step is to use the model to predict actions and interact with the environment.
[ ]:
for i in range(episodes):
obs, info = evaluation_env.reset()
rewards = []
truncated = terminated = False
current_month = 0
while not (terminated or truncated):
a, _ = model.predict(obs)
obs, reward, terminated, truncated, info = evaluation_env.step(a)
rewards.append(reward)
if info['month'] != current_month:
current_month = info['month']
print(info['month'], sum(rewards))
print(
'Episode ',
i,
'Mean reward: ',
np.mean(rewards),
'Cumulative reward: ',
sum(rewards))
evaluation_env.close()
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40] [Episode 7]
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run7]
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model. [USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw]
[ENVIRONMENT] (INFO) : Saving episode output path... [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run7/output]
/usr/local/lib/python3.12/dist-packages/opyplus/weather_data/weather_data.py:485: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.replace(
[SIMULATOR] (INFO) : Running EnergyPlus with args: ['-w', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run7/USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3_Random_1.0_0.0_0.001.epw', '-d', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run7/output', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run7/5ZoneAutoDXVAV.epJSON']
[ENVIRONMENT] (INFO) : Episode 7 started.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
1 -1.6446008069134792
2 -2535.9359450953466-----------------------------------------------------------------------------------------| 9%
3 -4823.4260633241665******-----------------------------------------------------------------------------------| 16%
4 -7364.053050786045****************--------------------------------------------------------------------------| 25%
5 -10181.732275386925***********************------------------------------------------------------------------| 33%
6 -13215.13622884691********************************----------------------------------------------------------| 41%
7 -14626.421671023001****************************************-------------------------------------------------| 50%
8 -16211.2274234831*************************************************------------------------------------------| 58%
9 -17762.154093987843********************************************************---------------------------------| 66%
10 -19114.586326032266****************************************************************------------------------| 75%
11 -22079.542120929047************************************************************************----------------| 83%
12 -24505.240849155747********************************************************************************--------| 91%
Progress: |***************************************************************************************************| 99%
Episode 0 Mean reward: -0.7698908037188604 Cumulative reward: -26977.743653112586
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40] [Episode 8]
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run8]
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model. [USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw]
[ENVIRONMENT] (INFO) : Saving episode output path... [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run8/output]
/usr/local/lib/python3.12/dist-packages/opyplus/weather_data/weather_data.py:485: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.replace(
[SIMULATOR] (INFO) : Running EnergyPlus with args: ['-w', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run8/USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3_Random_1.0_0.0_0.001.epw', '-d', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run8/output', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run8/5ZoneAutoDXVAV.epJSON']
[ENVIRONMENT] (INFO) : Episode 8 started.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
1 -1.7995207922238332
2 -2525.907934259986------------------------------------------------------------------------------------------| 9%
3 -4833.829075719896*******-----------------------------------------------------------------------------------| 16%
4 -7383.058739944303****************--------------------------------------------------------------------------| 25%
5 -10135.751693178638***********************------------------------------------------------------------------| 33%
6 -13203.476618527327*******************************----------------------------------------------------------| 41%
7 -14631.222012238866****************************************-------------------------------------------------| 50%
8 -16232.522719327082***********************************************------------------------------------------| 58%
9 -17753.958387954357********************************************************---------------------------------| 66%
10 -19146.864311365585****************************************************************------------------------| 75%
11 -22069.136934518898************************************************************************----------------| 83%
12 -24526.976100128184********************************************************************************--------| 91%
Progress: |***************************************************************************************************| 99%
Episode 1 Mean reward: -0.7699928837281512 Cumulative reward: -26980.550645834417
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40] [Episode 9]
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run9]
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model. [USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw]
[ENVIRONMENT] (INFO) : Saving episode output path... [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run9/output]
/usr/local/lib/python3.12/dist-packages/opyplus/weather_data/weather_data.py:485: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.replace(
[SIMULATOR] (INFO) : Running EnergyPlus with args: ['-w', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run9/USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3_Random_1.0_0.0_0.001.epw', '-d', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run9/output', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run9/5ZoneAutoDXVAV.epJSON']
[ENVIRONMENT] (INFO) : Episode 9 started.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
1 -1.7933100220830442
2 -2538.445643551368------------------------------------------------------------------------------------------| 9%
3 -4836.026266378525*******-----------------------------------------------------------------------------------| 16%
4 -7398.170606903661****************--------------------------------------------------------------------------| 25%
5 -10215.490911458011***********************------------------------------------------------------------------| 33%
6 -13270.859682680994*******************************----------------------------------------------------------| 41%
7 -14673.470077032065****************************************-------------------------------------------------| 50%
8 -16277.010656826511***********************************************------------------------------------------| 58%
9 -17859.96995901266*********************************************************---------------------------------| 66%
10 -19229.724716059914****************************************************************------------------------| 75%
11 -22190.489836264052************************************************************************----------------| 83%
12 -24654.54683199728*********************************************************************************--------| 91%
Progress: |***************************************************************************************************| 99%
Episode 2 Mean reward: -0.7740173991820579 Cumulative reward: -27121.569667339314
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40] [Episode 10]
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run10]
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model. [USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw]
[ENVIRONMENT] (INFO) : Saving episode output path... [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run10/output]
[SIMULATOR] (INFO) : Running EnergyPlus with args: ['-w', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run10/USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3_Random_1.0_0.0_0.001.epw', '-d', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run10/output', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run10/5ZoneAutoDXVAV.epJSON']
[ENVIRONMENT] (INFO) : Episode 10 started.
/usr/local/lib/python3.12/dist-packages/opyplus/weather_data/weather_data.py:485: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.replace(
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
1 -1.7162450174060817
2 -2515.235832234475------------------------------------------------------------------------------------------| 9%
3 -4835.124638771841*******-----------------------------------------------------------------------------------| 16%
4 -7407.433874239768****************--------------------------------------------------------------------------| 25%
5 -10197.88881457567************************------------------------------------------------------------------| 33%
6 -13209.917010355572*******************************----------------------------------------------------------| 41%
7 -14581.792369056018****************************************-------------------------------------------------| 50%
8 -16196.423742594645***********************************************------------------------------------------| 58%
9 -17691.01897293819*********************************************************---------------------------------| 66%
10 -19067.20513247273*****************************************************************------------------------| 75%
11 -22016.093939425933************************************************************************----------------| 83%
12 -24454.153731838967********************************************************************************--------| 91%
Progress: |***************************************************************************************************| 99%
Episode 3 Mean reward: -0.7670151345390938 Cumulative reward: -26876.210314249845
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40] [Episode 11]
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run11]
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model. [USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw]
[ENVIRONMENT] (INFO) : Saving episode output path... [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run11/output]
[SIMULATOR] (INFO) : Running EnergyPlus with args: ['-w', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run11/USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3_Random_1.0_0.0_0.001.epw', '-d', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run11/output', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run11/5ZoneAutoDXVAV.epJSON']
[ENVIRONMENT] (INFO) : Episode 11 started.
/usr/local/lib/python3.12/dist-packages/opyplus/weather_data/weather_data.py:485: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.replace(
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
1 -1.9855085492179452
2 -2525.9765795852795-----------------------------------------------------------------------------------------| 9%
3 -4836.447992908011*******-----------------------------------------------------------------------------------| 16%
4 -7415.106488666047****************--------------------------------------------------------------------------| 25%
5 -10199.115705433655***********************------------------------------------------------------------------| 33%
6 -13226.748838894438*******************************----------------------------------------------------------| 41%
7 -14570.022002702428****************************************-------------------------------------------------| 50%
8 -16163.73052129073************************************************------------------------------------------| 58%
9 -17710.726350820067********************************************************---------------------------------| 66%
10 -19090.64622045218*****************************************************************------------------------| 75%
11 -22118.184102555933************************************************************************----------------| 83%
12 -24523.10955600609*********************************************************************************--------| 91%
Progress: |***************************************************************************************************| 99%
Episode 4 Mean reward: -0.770449260651564 Cumulative reward: -26996.542093230804
[WRAPPER CSVLogger] (INFO) : Environment closed, data updated in monitor and progress.csv.
[WRAPPER CSVLogger] (INFO) : Environment closed, data updated in monitor and progress.csv.
[ENVIRONMENT] (INFO) : Environment closed. [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
The results obtained by the loaded model are stored locally, but can also be monitored through WandB if WandBLogger was used.
When checking out the WandB project list, you will see that the
sinergym_evaluationsproject now includes a new run:
This includes the set of tracked hyperparameters, and the previous training artifact used to load the model:
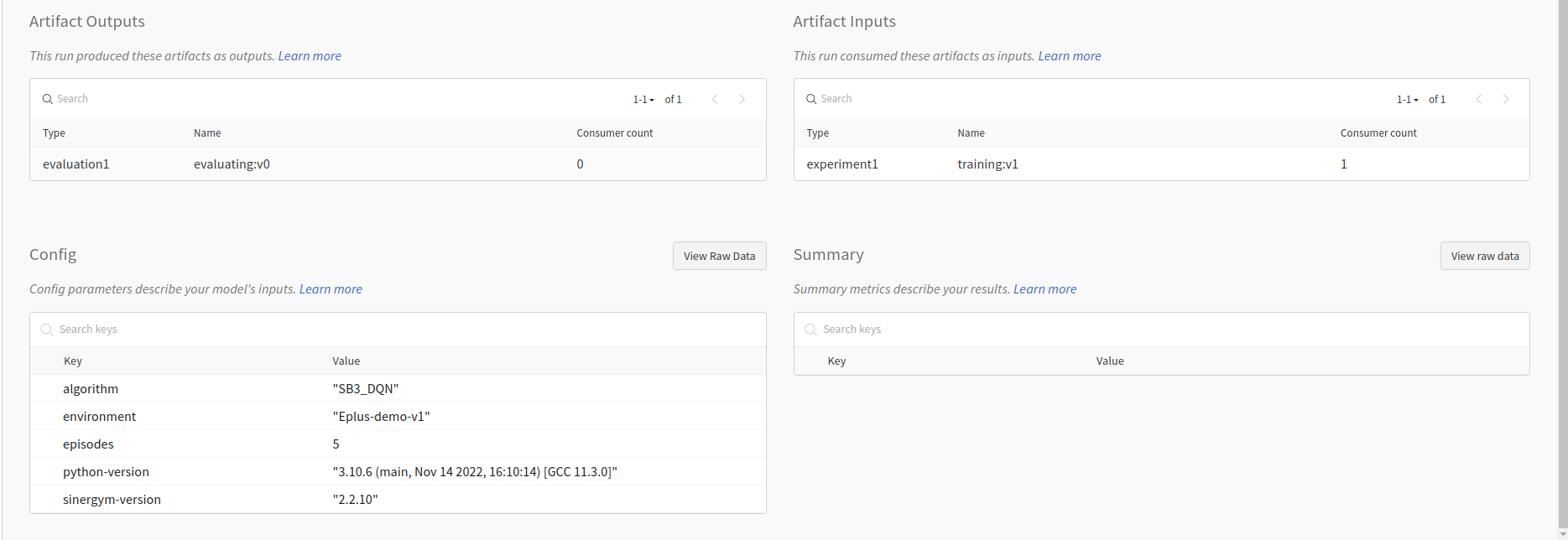
The evaluation output, containing the registered artifact and CSV files created by the logger:
