26. DRL usage example
In this notebook example, we’ve used Stable Baselines 3 to train and load an agent. However, Sinergym is entirely agnostic to any DRL algorithm (though it does have custom callbacks specifically for SB3) and can be used with any DRL library that interfaces with Gymnasium.
26.1. Training a model
We’ll be using the train_agent.py script located in the repository root. This script leverages all the capabilities of Sinergym for working with deep reinforcement learning algorithms and sets parameters for everything, allowing us to easily define training options via a JSON file when executing the script.
For more details on how to run train_agent.py, please refer to Train a model.
[1]:
import sys
from datetime import datetime
import gymnasium as gym
import numpy as np
import wandb
from stable_baselines3 import *
from stable_baselines3.common.callbacks import CallbackList
from stable_baselines3.common.logger import HumanOutputFormat
from stable_baselines3.common.logger import Logger as SB3Logger
import sinergym
from sinergym.utils.callbacks import *
from sinergym.utils.constants import *
from sinergym.utils.logger import WandBOutputFormat
from sinergym.utils.rewards import *
from sinergym.utils.wrappers import *
First, let’s set some variables for the execution.
[2]:
# Environment ID
environment = "Eplus-5zone-mixed-continuous-stochastic-v1"
# Training episodes
episodes = 5
#Name of the experiment
experiment_date = datetime.today().strftime('%Y-%m-%d_%H:%M')
experiment_name = 'SB3_PPO-' + environment + \
'-episodes-' + str(episodes)
experiment_name += '_' + experiment_date
Now, we’re ready to create the Gym environment. We’ll use the previously defined environment name, but remember that you can change the default environment configuration. We’ll also create an eval_env for evaluation episodes. If desired, we can replace the env name with the experiment name.
[3]:
env = gym.make(environment, env_name=experiment_name)
eval_env = gym.make(environment, env_name=experiment_name+'_EVALUATION')
#==============================================================================================#
[ENVIRONMENT] (INFO) : Creating Gymnasium environment... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-20_11:17]
#==============================================================================================#
[MODELING] (INFO) : Experiment working directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-20_11:17-res1]
[MODELING] (INFO) : Model Config is correct.
[MODELING] (INFO) : Updated building model with whole Output:Variable available names
[MODELING] (INFO) : Updated building model with whole Output:Meter available names
[MODELING] (INFO) : runperiod established: {'start_day': 1, 'start_month': 1, 'start_year': 1991, 'end_day': 31, 'end_month': 12, 'end_year': 1991, 'start_weekday': 0, 'n_steps_per_hour': 4}
[MODELING] (INFO) : Episode length (seconds): 31536000.0
[MODELING] (INFO) : timestep size (seconds): 900.0
[MODELING] (INFO) : timesteps per episode: 35041
[REWARD] (INFO) : Reward function initialized.
[ENVIRONMENT] (INFO) : Environment SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-20_11:17 created successfully.
#==============================================================================================#
[ENVIRONMENT] (INFO) : Creating Gymnasium environment... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-20_11:17_EVALUATION]
#==============================================================================================#
[MODELING] (INFO) : Experiment working directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-20_11:17_EVALUATION-res1]
[MODELING] (INFO) : Model Config is correct.
[MODELING] (INFO) : Updated building model with whole Output:Variable available names
[MODELING] (INFO) : Updated building model with whole Output:Meter available names
[MODELING] (INFO) : runperiod established: {'start_day': 1, 'start_month': 1, 'start_year': 1991, 'end_day': 31, 'end_month': 12, 'end_year': 1991, 'start_weekday': 0, 'n_steps_per_hour': 4}
[MODELING] (INFO) : Episode length (seconds): 31536000.0
[MODELING] (INFO) : timestep size (seconds): 900.0
[MODELING] (INFO) : timesteps per episode: 35041
[REWARD] (INFO) : Reward function initialized.
[ENVIRONMENT] (INFO) : Environment SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-20_11:17_EVALUATION created successfully.
We can also add wrappers to the environment. We’ll use an action and observation normalization wrapper and Sinergym logger. Normalization is highly recommended for DRL algorithms with continuous action space, and the logger is used to monitor and log environment interactions and save the data, and then dump it into CSV files and/or wandb.
[4]:
env = NormalizeObservation(env)
env = NormalizeAction(env)
env = LoggerWrapper(env)
env = CSVLogger(env)
# Discomment the following line to log to WandB (remmeber to set the API key in a environment variable)
# env = WandBLogger(env,
# entity='sinergym',
# project_name='sail_ugr',
# run_name=experiment_name,
# group='Train_example',
# tags=['DRL', 'PPO', '5zone', 'continuous', 'stochastic', 'v1'],
# save_code = True,
# dump_frequency = 1000,
# artifact_save = True)
eval_env = NormalizeObservation(eval_env)
eval_env = NormalizeAction(eval_env)
eval_env = LoggerWrapper(eval_env)
eval_env = CSVLogger(eval_env)
# Evaluation env is not required to wrapp with WandBLogger since the calculations are added in the same WandB session than the training env,
# using the sinergym LoggerEvalCallback
[WRAPPER NormalizeObservation] (INFO) : Wrapper initialized.
[WRAPPER NormalizeAction] (INFO) : New normalized action Space: Box(-1.0, 1.0, (2,), float32)
[WRAPPER NormalizeAction] (INFO) : Wrapper initialized
[WRAPPER LoggerWrapper] (INFO) : Wrapper initialized.
[WRAPPER CSVLogger] (INFO) : Wrapper initialized.
[WRAPPER NormalizeObservation] (INFO) : Wrapper initialized.
[WRAPPER NormalizeAction] (INFO) : New normalized action Space: Box(-1.0, 1.0, (2,), float32)
[WRAPPER NormalizeAction] (INFO) : Wrapper initialized
[WRAPPER LoggerWrapper] (INFO) : Wrapper initialized.
[WRAPPER CSVLogger] (INFO) : Wrapper initialized.
At this point, the environment is set up and ready to use. We’ll create our learning model (Stable Baselines 3 PPO), but any other algorithm can be used.
[5]:
# In this case, all the hyperparameters are the default ones
model = PPO('MlpPolicy', env, verbose=1)
Using cpu device
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
If WandBLogger is active, we can log all hyperparameters there:
[6]:
# Register hyperparameters in wandb if it is wrapped
if is_wrapped(env, WandBLogger):
experiment_params = {
'sinergym-version': sinergym.__version__,
'python-version': sys.version
}
# experiment_params.update(conf)
env.get_wrapper_attr('wandb_run').config.update(experiment_params)
Evaluation will run the current model for a set number of episodes to determine if it’s the best current version of the model at that training stage. The generated output will also be stored depending used logger wrappers. We’ll use the LoggerEval callback to print and save the best evaluated model during training, saving in local CSV files and WandB platform.
[7]:
callbacks = []
# Set up Evaluation logging and saving best model
eval_callback = LoggerEvalCallback(
eval_env=eval_env,
train_env=env,
n_eval_episodes=1,
eval_freq_episodes=2,
deterministic=True)
callbacks.append(eval_callback)
callback = CallbackList(callbacks)
To add the SB3 logging values in the same WandB session too, we need to create a compatible wandb output format (which calls the wandb log method in the learning algorithm process). Sinergym has implemented one called WandBOutputFormat.
[8]:
# wandb logger and setting in SB3
if is_wrapped(env, WandBLogger):
# wandb logger and setting in SB3
logger = SB3Logger(
folder=None,
output_formats=[
HumanOutputFormat(
sys.stdout,
max_length=120),
WandBOutputFormat()])
model.set_logger(logger)
This is the total number of time steps for the training.
[9]:
timesteps = episodes * (env.get_wrapper_attr('timestep_per_episode') - 1)
Now, it’s time to train the model with the previously defined callback. This may take a few minutes, depending on your computer.
[ ]:
model.learn(
total_timesteps=timesteps,
callback=callback,
log_interval=100)
Now, we save the current model (the model version when training has finished). We will save the mean and var normalization calibration in order to use it in model evaluation, although these values can be consulted later in a txt saved in Sinergym training output. Visit NormalizeObservation wrapper documentation for more information.
[ ]:
model.save(env.get_wrapper_attr('workspace_path') + '/model')
And as always, remember to close the environment. If WandB is active with logger, this close will save artifacts with whole experiment output and evaluation executed.
[ ]:
env.close()
[WRAPPER CSVLogger] (INFO) : Environment closed, data updated in monitor and progress.csv.
[ENVIRONMENT] (INFO) : Environment closed. [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
Progress: |***************************************************************************************************| 99%
All experiment results are stored locally, but you can also view the execution in wandb:
When you check your projects, you’ll see the execution allocated:
The training experiment’s tracked hyperparameters:

Registered artifacts (if evaluation is enabled, the best model is also registered):

Real-time visualization of metrics:
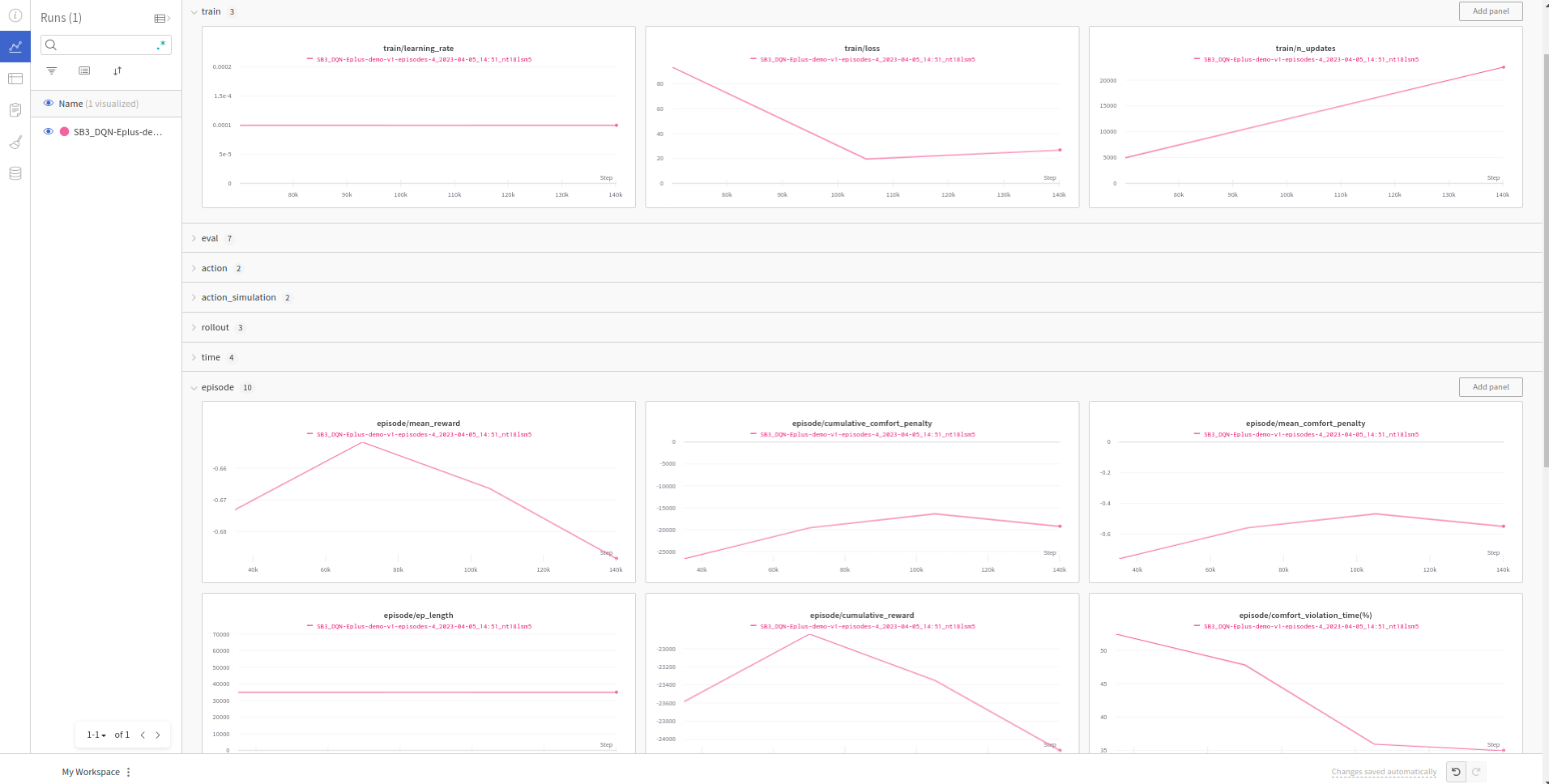
26.2. Loading a model
We’ll be using the load_agent.py script located in the repository root. This script leverages all the capabilities of Sinergym for working with loaded deep reinforcement learning models and sets parameters for everything, allowing us to easily define load options via a JSON file when executing the script.
For more details on how to run load_agent.py, please refer to Load a trained model.
First, we’ll define the Sinergym environment ID where we want to test the loaded agent and the name of the evaluation experiment.
[ ]:
# Environment ID
environment = "Eplus-5zone-mixed-continuous-stochastic-v1"
# Episodes
episodes=5
# Evaluation name
evaluation_date = datetime.today().strftime('%Y-%m-%d_%H:%M')
evaluation_name = 'SB3_PPO-EVAL-' + environment + \
'-episodes-' + str(episodes)
evaluation_name += '_' + evaluation_date
We’ll create the Gym environment, but it’s important to wrap the environment with the same wrappers, whose action and observation observation spaces were modified, used during training. We can use the evaluation experiment name to rename the environment.
Note: If you are loading a pre-trained model and using the observation space normalization wrapper, you should use the means and variations calibrated during the training process for a fair evaluation. The next code specifies this aspect, those mean and var values are written in Sinergym training output as txt file automatically if you want to consult it later. You can use the list/numpy array values or set the txt path directly in the field constructor. It is also important to deactivate
calibration update during evaluations. Check the documentation on the wrapper for more information. This task is done automatically in LoggerEvalCallback.
[ ]:
evaluation_env = gym.make(environment, env_name=evaluation_name)
evaluation_env = NormalizeObservation(evaluation_env, mean = env.get_wrapper_attr("mean"), var = env.get_wrapper_attr("var"), automatic_update=False)
evaluation_env = NormalizeAction(evaluation_env)
evaluation_env = LoggerWrapper(evaluation_env)
evaluation_env = CSVLogger(evaluation_env)
# If you want to log the evaluation interactions to WandB, use WandBLogger too
#==============================================================================================#
[ENVIRONMENT] (INFO) : Creating Gymnasium environment... [SB3_PPO-EVAL-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:48]
#==============================================================================================#
[MODELING] (INFO) : Experiment working directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-EVAL-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:48-res1]
[MODELING] (INFO) : Model Config is correct.
[MODELING] (INFO) : Updated building model with whole Output:Variable available names
[MODELING] (INFO) : Updated building model with whole Output:Meter available names
[MODELING] (INFO) : runperiod established: {'start_day': 1, 'start_month': 1, 'start_year': 1991, 'end_day': 31, 'end_month': 12, 'end_year': 1991, 'start_weekday': 0, 'n_steps_per_hour': 4}
[MODELING] (INFO) : Episode length (seconds): 31536000.0
[MODELING] (INFO) : timestep size (seconds): 900.0
[MODELING] (INFO) : timesteps per episode: 35041
[REWARD] (INFO) : Reward function initialized.
[ENVIRONMENT] (INFO) : Environment SB3_PPO-EVAL-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:48 created successfully.
[WRAPPER NormalizeObservation] (INFO) : Wrapper initialized.
[WRAPPER NormalizeAction] (INFO) : New normalized action Space: Box(-1.0, 1.0, (2,), float32)
[WRAPPER NormalizeAction] (INFO) : Wrapper initialized
[WRAPPER LoggerWrapper] (INFO) : Wrapper initialized.
[WRAPPER CSVLogger] (INFO) : Wrapper initialized.
We’ll load the Stable Baselines 3 PPO model from our local computer, but we could also use a remote model stored in wandb from another training experiment.
[ ]:
# get wandb artifact path (to load model)
if is_wrapped(evaluation_env, WandBLogger):
wandb_run = evaluation_env.get_wrapper_attr('wandb_run')
else:
wandb_run = wandb.init(entity = 'sail_ugr')
load_artifact_entity = 'sail_ugr'
load_artifact_project = 'sinergym'
load_artifact_name = experiment_name
load_artifact_tag = 'latest'
load_artifact_model_path = 'Sinergym_output/evaluation/best_model.zip'
wandb_path = load_artifact_entity + '/' + load_artifact_project + \
'/' + load_artifact_name + ':' + load_artifact_tag
# Download artifact
artifact = wandb_run.use_artifact(wandb_path)
artifact.get_path(load_artifact_model_path).download('.')
# Set model path to local wandb file downloaded
model_path = './' + load_artifact_model_path
model = PPO.load(model_path)
As you can see, the wandb model we want to load can come from an artifact of a different entity or project than the one we’re using to register the evaluation of the loaded model, as long as it’s accessible. The next step is to use the model to predict actions and interact with the environment to collect data for model evaluation.
[ ]:
for i in range(episodes):
obs, info = evaluation_env.reset()
rewards = []
truncated = terminated = False
current_month = 0
while not (terminated or truncated):
a, _ = model.predict(obs)
obs, reward, terminated, truncated, info = evaluation_env.step(a)
rewards.append(reward)
if info['month'] != current_month:
current_month = info['month']
print(info['month'], sum(rewards))
print(
'Episode ',
i,
'Mean reward: ',
np.mean(rewards),
'Cumulative reward: ',
sum(rewards))
evaluation_env.close()
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40] [Episode 7]
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run7]
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model. [USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw]
[ENVIRONMENT] (INFO) : Saving episode output path... [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run7/output]
/usr/local/lib/python3.12/dist-packages/opyplus/weather_data/weather_data.py:485: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.replace(
[SIMULATOR] (INFO) : Running EnergyPlus with args: ['-w', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run7/USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3_Random_1.0_0.0_0.001.epw', '-d', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run7/output', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run7/5ZoneAutoDXVAV.epJSON']
[ENVIRONMENT] (INFO) : Episode 7 started.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
1 -1.6446008069134792
2 -2535.9359450953466-----------------------------------------------------------------------------------------| 9%
3 -4823.4260633241665******-----------------------------------------------------------------------------------| 16%
4 -7364.053050786045****************--------------------------------------------------------------------------| 25%
5 -10181.732275386925***********************------------------------------------------------------------------| 33%
6 -13215.13622884691********************************----------------------------------------------------------| 41%
7 -14626.421671023001****************************************-------------------------------------------------| 50%
8 -16211.2274234831*************************************************------------------------------------------| 58%
9 -17762.154093987843********************************************************---------------------------------| 66%
10 -19114.586326032266****************************************************************------------------------| 75%
11 -22079.542120929047************************************************************************----------------| 83%
12 -24505.240849155747********************************************************************************--------| 91%
Progress: |***************************************************************************************************| 99%
Episode 0 Mean reward: -0.7698908037188604 Cumulative reward: -26977.743653112586
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40] [Episode 8]
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run8]
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model. [USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw]
[ENVIRONMENT] (INFO) : Saving episode output path... [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run8/output]
/usr/local/lib/python3.12/dist-packages/opyplus/weather_data/weather_data.py:485: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.replace(
[SIMULATOR] (INFO) : Running EnergyPlus with args: ['-w', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run8/USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3_Random_1.0_0.0_0.001.epw', '-d', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run8/output', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run8/5ZoneAutoDXVAV.epJSON']
[ENVIRONMENT] (INFO) : Episode 8 started.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
1 -1.7995207922238332
2 -2525.907934259986------------------------------------------------------------------------------------------| 9%
3 -4833.829075719896*******-----------------------------------------------------------------------------------| 16%
4 -7383.058739944303****************--------------------------------------------------------------------------| 25%
5 -10135.751693178638***********************------------------------------------------------------------------| 33%
6 -13203.476618527327*******************************----------------------------------------------------------| 41%
7 -14631.222012238866****************************************-------------------------------------------------| 50%
8 -16232.522719327082***********************************************------------------------------------------| 58%
9 -17753.958387954357********************************************************---------------------------------| 66%
10 -19146.864311365585****************************************************************------------------------| 75%
11 -22069.136934518898************************************************************************----------------| 83%
12 -24526.976100128184********************************************************************************--------| 91%
Progress: |***************************************************************************************************| 99%
Episode 1 Mean reward: -0.7699928837281512 Cumulative reward: -26980.550645834417
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40] [Episode 9]
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run9]
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model. [USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw]
[ENVIRONMENT] (INFO) : Saving episode output path... [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run9/output]
/usr/local/lib/python3.12/dist-packages/opyplus/weather_data/weather_data.py:485: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.replace(
[SIMULATOR] (INFO) : Running EnergyPlus with args: ['-w', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run9/USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3_Random_1.0_0.0_0.001.epw', '-d', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run9/output', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run9/5ZoneAutoDXVAV.epJSON']
[ENVIRONMENT] (INFO) : Episode 9 started.
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
1 -1.7933100220830442
2 -2538.445643551368------------------------------------------------------------------------------------------| 9%
3 -4836.026266378525*******-----------------------------------------------------------------------------------| 16%
4 -7398.170606903661****************--------------------------------------------------------------------------| 25%
5 -10215.490911458011***********************------------------------------------------------------------------| 33%
6 -13270.859682680994*******************************----------------------------------------------------------| 41%
7 -14673.470077032065****************************************-------------------------------------------------| 50%
8 -16277.010656826511***********************************************------------------------------------------| 58%
9 -17859.96995901266*********************************************************---------------------------------| 66%
10 -19229.724716059914****************************************************************------------------------| 75%
11 -22190.489836264052************************************************************************----------------| 83%
12 -24654.54683199728*********************************************************************************--------| 91%
Progress: |***************************************************************************************************| 99%
Episode 2 Mean reward: -0.7740173991820579 Cumulative reward: -27121.569667339314
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40] [Episode 10]
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run10]
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model. [USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw]
[ENVIRONMENT] (INFO) : Saving episode output path... [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run10/output]
[SIMULATOR] (INFO) : Running EnergyPlus with args: ['-w', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run10/USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3_Random_1.0_0.0_0.001.epw', '-d', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run10/output', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run10/5ZoneAutoDXVAV.epJSON']
[ENVIRONMENT] (INFO) : Episode 10 started.
/usr/local/lib/python3.12/dist-packages/opyplus/weather_data/weather_data.py:485: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.replace(
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
1 -1.7162450174060817
2 -2515.235832234475------------------------------------------------------------------------------------------| 9%
3 -4835.124638771841*******-----------------------------------------------------------------------------------| 16%
4 -7407.433874239768****************--------------------------------------------------------------------------| 25%
5 -10197.88881457567************************------------------------------------------------------------------| 33%
6 -13209.917010355572*******************************----------------------------------------------------------| 41%
7 -14581.792369056018****************************************-------------------------------------------------| 50%
8 -16196.423742594645***********************************************------------------------------------------| 58%
9 -17691.01897293819*********************************************************---------------------------------| 66%
10 -19067.20513247273*****************************************************************------------------------| 75%
11 -22016.093939425933************************************************************************----------------| 83%
12 -24454.153731838967********************************************************************************--------| 91%
Progress: |***************************************************************************************************| 99%
Episode 3 Mean reward: -0.7670151345390938 Cumulative reward: -26876.210314249845
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
[WRAPPER CSVLogger] (INFO) : End of episode detected, data updated in monitor and progress.csv.
#----------------------------------------------------------------------------------------------#
[ENVIRONMENT] (INFO) : Starting a new episode... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40] [Episode 11]
#----------------------------------------------------------------------------------------------#
[MODELING] (INFO) : Episode directory created [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run11]
[MODELING] (INFO) : Weather file USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw used.
[MODELING] (INFO) : Adapting weather to building model. [USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3.epw]
[ENVIRONMENT] (INFO) : Saving episode output path... [/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run11/output]
[SIMULATOR] (INFO) : Running EnergyPlus with args: ['-w', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run11/USA_NY_New.York-J.F.Kennedy.Intl.AP.744860_TMY3_Random_1.0_0.0_0.001.epw', '-d', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run11/output', '/workspaces/sinergym/examples/Eplus-env-SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40-res1/Eplus-env-sub_run11/5ZoneAutoDXVAV.epJSON']
[ENVIRONMENT] (INFO) : Episode 11 started.
/usr/local/lib/python3.12/dist-packages/opyplus/weather_data/weather_data.py:485: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df = df.replace(
[SIMULATOR] (INFO) : handlers are ready.
[SIMULATOR] (INFO) : System is ready.
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
1 -1.9855085492179452
2 -2525.9765795852795-----------------------------------------------------------------------------------------| 9%
3 -4836.447992908011*******-----------------------------------------------------------------------------------| 16%
4 -7415.106488666047****************--------------------------------------------------------------------------| 25%
5 -10199.115705433655***********************------------------------------------------------------------------| 33%
6 -13226.748838894438*******************************----------------------------------------------------------| 41%
7 -14570.022002702428****************************************-------------------------------------------------| 50%
8 -16163.73052129073************************************************------------------------------------------| 58%
9 -17710.726350820067********************************************************---------------------------------| 66%
10 -19090.64622045218*****************************************************************------------------------| 75%
11 -22118.184102555933************************************************************************----------------| 83%
12 -24523.10955600609*********************************************************************************--------| 91%
Progress: |***************************************************************************************************| 99%
Episode 4 Mean reward: -0.770449260651564 Cumulative reward: -26996.542093230804
[WRAPPER CSVLogger] (INFO) : Environment closed, data updated in monitor and progress.csv.
[WRAPPER CSVLogger] (INFO) : Environment closed, data updated in monitor and progress.csv.
[ENVIRONMENT] (INFO) : Environment closed. [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
[WRAPPER NormalizeObservation] (INFO) : Saving normalization calibration data... [SB3_PPO-Eplus-5zone-mixed-continuous-stochastic-v1-episodes-5_2024-08-07_15:40]
The results from the loaded model are stored locally, but you can also view the execution in wandb if WandBLogger were used:
When you check the wandb project list, you’ll see that the sinergym_evaluations project has a new run:
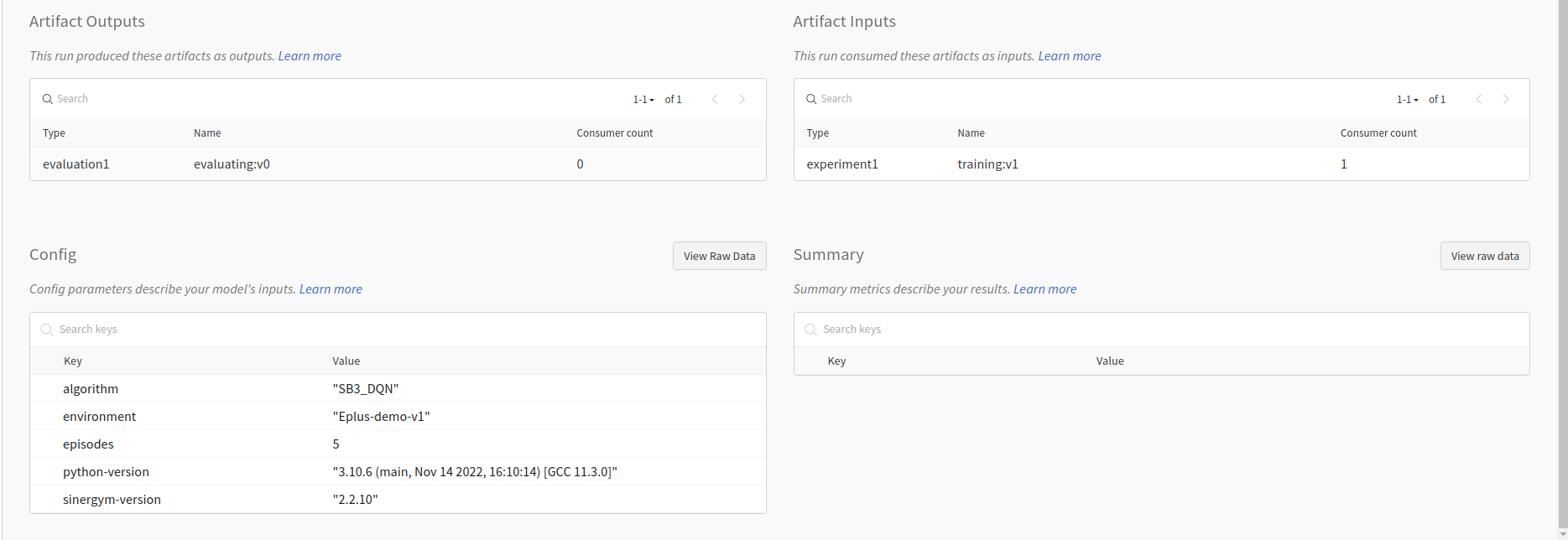
The evaluation experiment’s tracked hyperparameters, and the previous training artifact used to load the model:
The registered artifact with Sinergym Output (and CSV files generated with the Logger Wrapper):
